A la recherche d'un détail Bright Data Examen du navigateur de grattage, Ne vous inquiétez pas, je vous ai couvert.
Internet est un énorme réservoir de données qui peut être extrêmement précieux pour les entreprises, les chercheurs et les particuliers. Cependant, l'accès à ces données peut être une tâche ardue, en particulier lorsqu'il s'agit de grattage de données.
Le grattage de données est le processus d'extraction automatique de données à partir de sites Web, et il est souvent utilisé à des fins de recherche, de marketing et à d'autres fins.
Le grattage des données peut être effectué manuellement, mais il s'agit d'un processus qui prend du temps et nécessite une grande expertise technique.
Heureusement, il existe des outils logiciels et des services disponibles qui peuvent automatiser le processus de récupération des données et faciliter l'accès aux données dont vous avez besoin.
Mais cela peut également être difficile, en particulier lorsqu'il s'agit de blocs de site, de CAPTCHA et d'autres scripts de détection de robots. Le coût total moyen d'une violation de données est de 3.62 millions de dollars en 2017, soit une baisse de 10 % par rapport à l'année dernière.
C'est là que le Bright Data Scraping Browser entre en jeu. Alors, discutons en détail de la façon dont le Bright Data Scraping Browser vous aide à gratter les données dans notre détail Bright Data Examen du navigateur de grattage.

Quel est Bright Data Scraper le navigateur ?
La Bright Data Navigateur de grattage est un navigateur automatisé tout-en-un conçu spécifiquement à des fins de récupération de données.
Il est alimenté par un réseau proxy primé qui offre plus de 72 millions d'adresses IP et la possibilité de cibler n'importe quel pays, ville, transporteur et ASN.
Cette prime service proxy est un excellent choix pour les développeurs qui ont besoin de récupérer des données à grande échelle. De plus, il est compatible avec Puppeteer, ce qui signifie qu'il est plus puissant que les navigateurs automatisés et sans tête.
La Bright Data Scraping Browser est conçu pour rendre le scraping de données rapide, facile et sécurisé. Il utilise des technologies avancées telles que le captcha piloté par l'IA et la détection de robots qui garantissent une extraction fluide des données.
Avec la Bright Data Scraping Browser, les utilisateurs peuvent extraire rapidement et en toute sécurité des données de n'importe quel site Web sans aucun problème.
Les caractéristiques de Bright Data Navigateur de grattage
Bright DataLe navigateur de grattage de offre un certain nombre de fonctionnalités conçues pour vous aider à Web Scraping À l'échelle.
1. Gestion automatique des opérations de déverrouillage du site Web
Le programme a une fonctionnalité clé de gestion automatique des opérations de déverrouillage du site Web. Cela inclut la résolution des CAPTCHA, les navigateurs d'empreintes digitales et une variété d'autres tâches.
Cela peut faire gagner du temps et des ressources aux développeurs qui ont besoin de récupérer de grandes quantités de données sur des sites Web.
2. Logiciel de détection de robots Outsmart
Une autre caractéristique importante de Bright DataLe navigateur de scraping de est sa capacité à déjouer les logiciels de détection de robots.
En plus de contourner systèmes de détection de robots en utilisant la technologie AI, les scrapers peuvent également produire de meilleurs taux de déverrouillage lors de l'utilisation de proxys au lieu de la technologie AI.

3. Hautement évolutif
Bright DataLe navigateur de scraping de est également hautement évolutif, permettant aux développeurs de développer leurs projets de scraping avec autant de navigateurs qu'ils en ont besoin.
Les navigateurs sont hébergés sur Bright DataL'infrastructure de , conçue pour gérer de grandes quantités de trafic et de requêtes.
4. Compatible avec Puppeteer (Python) et Playwright (Node.js)
Enfin, Bright DataLe navigateur de grattage de est compatible avec Puppeteer (Python) et Playwright (Node.js), ce qui permet aux développeurs d'interagir avec les sessions du navigateur et d'effectuer des interactions sur le site Web pour récupérer des données.
Cela peut être utile pour gratter des projets qui nécessitent de cliquer sur des boutons, de faire défiler ou d'ajouter du texte à des pages Web.
Prix
Le prix du Bright Data Scraping Browser est conçu pour être flexible et accessible aux entreprises de toutes tailles, des petites startups aux grandes entreprises.
La société propose quatre niveaux de tarification, notamment Pay As You Go, Growth, Business et Enterprise, pour répondre aux besoins des différents utilisateurs.
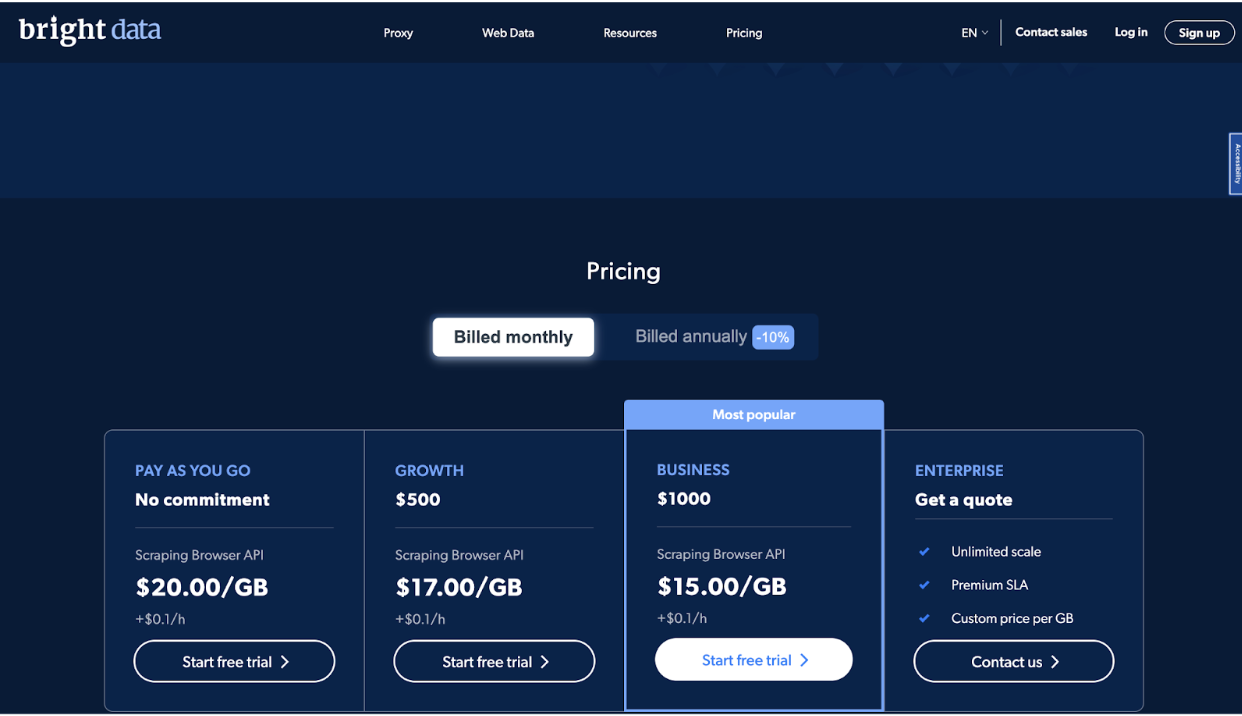
Le plan Pay As You Go est conçu pour les utilisateurs qui ont besoin de gratter des données occasionnellement ou en petits volumes. Il s'agit d'un plan sans engagement qui vous permet de ne payer que ce que vous utilisez. Le prix de ce plan est 20.00 $ par Go, plus 0.1 $ par heure.
Le plan de croissance est idéal pour les entreprises qui ont besoin de récupérer des données plus fréquemment ou en plus gros volumes. Il comprend un remise de 10% sur le Plan de paiement à l'utilisation et les frais 500 $ par mois. Le prix de ce plan est 17.00 $ par Go, plus 0.1 $ par heure.
Le plan d'affaires est le plan le plus populaire et est conçu pour les entreprises qui doivent faire évoluer leurs opérations de grattage de données.
Il comprend une remise de 25% sur le plan Pay As You Go et coûte 1000 $ par mois. Le prix de ce plan est 15.00 $ par Go, plus 0.1 $ par heure.
Enfin, le plan Enterprise est conçu pour les entreprises qui ont besoin d'une échelle illimitée et d'un accord de niveau de service premium (SLA).
La tarification de ce plan est personnalisée et est basée sur vos besoins et exigences spécifiques. Ce plan comprend des fonctionnalités telles que gestion de compte dédiée, tarification personnalisée par Go et assistance 24h/7 et XNUMXj/XNUMX.
De plus, si vous souhaitez ÉCONOMISER davantage, vous pouvez payer annuellement et économisez jusqu'à 40%.
Comment Scraping Browsers surpasse les navigateurs sans tête ?
Scraping Browser, un navigateur GUI (Graphical User Interface), surpasse les navigateurs sans tête de plusieurs manières lorsqu'il s'agit de mettre à l'échelle des projets de grattage de données et de contourner des blocs.
1. Contournement du logiciel de détection de robots
Les logiciels de détection de robots deviennent de plus en plus sophistiqués, ce qui rend difficile pour les développeurs de récupérer les données des sites Web.
Le logiciel de détection de robots est facilement capable de détecter les navigateurs sans tête, qui sont couramment utilisés pour gratter le Web.
Cependant, Scraping Browser est moins susceptible d'être détecté car il utilise une interface graphique, ce qui le fait ressembler davantage à un véritable navigateur utilisateur.
Cela signifie que les développeurs peuvent utiliser Scraping Browser pour récupérer des données sans se soucier d'être détectés et bloqués.
2. Fonctions de déverrouillage de site Web intégrées
Les blocs de sites Web sont automatiquement déverrouillés par Scraping Browser. Ces fonctions incluent la résolution des CAPTCHA, les empreintes digitales des navigateurs, les nouvelles tentatives automatiques, la sélection des en-têtes et des cookies, et le rendu JavaScript.
Cela signifie que les développeurs n'ont pas à consacrer du temps et des ressources à déverrouiller manuellement des sites Web ou à trouver des solutions de contournement pour le contenu bloqué. Scraping Browser s'occupe de tout automatiquement.

3. Facile à mettre à l'échelle
Scraping Browser est hébergé sur Bright Data, ce qui signifie que les développeurs peuvent facilement faire évoluer leurs projets de scraping Web en ouvrant autant de navigateurs de scraping qu'ils en ont besoin sans avoir à investir dans une infrastructure interne coûteuse.
Cela facilite la gestion de grands projets de récupération de données et garantit que les développeurs peuvent accéder rapidement et efficacement aux données dont ils ont besoin.
4. Capacité à interagir avec les sites Web
Un navigateur scraping est un navigateur GUI, ce qui signifie que les développeurs peuvent l'utiliser pour interagir avec des sites Web d'une manière qui n'est pas possible avec les navigateurs sans tête.
Par exemple, les développeurs peuvent survoler des pages, cliquer sur des boutons, faire défiler et ajouter du texte. Cela fait du Scraping Browser un choix idéal pour les projets de scraping Web qui nécessitent des interactions avec le site Web pour récupérer des données.
5. Capacités de débogage améliorées
Scraping Browser offre des capacités de débogage améliorées par rapport aux navigateurs sans tête.
Les développeurs peuvent utiliser l'interface graphique pour voir ce qui se passe sur le site Web en temps réel et peuvent facilement identifier les problèmes ou les erreurs qui se produisent pendant le processus de grattage.
Cela facilite la résolution des problèmes et garantit que les données sont récupérées correctement.
FAQ sur Bright Data Examen du navigateur de grattage 2024
👉 Quand faut-il utiliser un navigateur automatisé pour scraper ?
Les navigateurs automatisés sont utilisés pour le grattage des données lorsque le rendu JavaScript d'une page ou des interactions avec un site Web sont nécessaires, comme le survol, le changement de page, le clic et la prise de captures d'écran. Ils sont également utiles pour les projets de récupération de données à grande échelle ciblant plusieurs pages.
👉 Qu'est-ce que Scraping Browser ?
Scraping Browser est un navigateur automatisé contrôlé par des API de haut niveau telles que Puppeteer et Playwright. Le déblocage du site Web est automatiquement géré sous le capot, y compris la résolution CAPTCHA, les empreintes digitales, la sélection d'en-tête, les tentatives automatiques et le rendu JavaScript.
🤔 Scraping Browser est-il un navigateur headless ou headful ?
Le Scraping Browser utilise une interface utilisateur graphique et est également appelé navigateur headful. Cependant, les développeurs interagissent avec Scraping Browser via une API comme Puppeteer ou Playwright, ce qui le rend fonctionnellement sans tête. Scraping Browser est ouvert en tant que navigateur graphique sur Bright Datases infrastructures.
👉 Quelle est la différence entre un navigateur headless et un navigateur headful en matière de scraping ?
Les navigateurs sans tête font référence aux navigateurs Web sans interface utilisateur graphique, et ils peuvent être utilisés pour récupérer des données lorsqu'ils sont utilisés avec un proxy. Cependant, ils sont facilement détectés par les logiciels de protection contre les bots, ce qui rend difficile le grattage de données à grande échelle. Les navigateurs GUI, tels que Scraping Browser, utilisent une interface utilisateur graphique et sont moins susceptibles d'être détectés par un logiciel de détection de robots.
🤔 Qu'est-ce qui rend Scraping Browser supérieur au scraping Web Chrome Headless ou Python Selenium ?
Scraping Browser est livré avec une fonction de déblocage automatique qui supprime automatiquement les restrictions. Il est possible de mettre à l'échelle des projets de grattage de données Web sans exigences d'infrastructure en utilisant des navigateurs de grattage, qui utilisent un déverrouillage automatisé et s'exécutent sur Bright Datales serveurs.
👉 Scraping Browser est-il compatible avec le scraping Puppeteer ?
Oui, Scraping Browser est entièrement compatible avec Puppeteer.
🤔 Quand dois-je utiliser Scraping Browser au lieu d'autres Bright Data produits proxy ?
Scraping Browser est un navigateur automatisé dédié au scraping de données, alimenté par la technologie de déverrouillage automatisé de Web Unlocker. Scraper un navigateur est nécessaire lorsqu'un développeur doit interagir avec un site Web pour récupérer ses données. Il est également idéal pour tout projet de récupération de données qui nécessite des navigateurs, une mise à l'échelle et une gestion automatisée de toutes les actions de déblocage de sites Web.
Liens rapides:
Conclusion: Bright Data Examen du navigateur de grattage 2024
En conclusion, le grattage des données peut être une tâche difficile, en particulier lorsqu'il s'agit de bloquer des sites Web et d'autres scripts de détection de robots.
La Bright Data Scraping Browser est un navigateur automatisé tout-en-un qui rend le scraping de données plus facile et plus efficace.
Avec la compatibilité Puppeteer, le déblocage automatique des sites, la résolution CAPTCHA, les empreintes digitales, les tentatives, etc., il offre un large éventail de fonctionnalités et d'avantages.
C'est un excellent outil pour la mise à l'échelle, économise des ressources et du temps, et est idéal pour gérer des opérations de déverrouillage complexes.