Tìm kiếm một chi tiết Bright Data Đánh giá trình duyệt cạo, Đừng lo lắng tôi đã bảo vệ bạn.
Internet là một kho dữ liệu khổng lồ có thể vô cùng quý giá đối với các doanh nghiệp, nhà nghiên cứu và cá nhân. Tuy nhiên, việc truy cập dữ liệu này có thể là một nhiệm vụ khó khăn, đặc biệt là khi thu thập dữ liệu.
Quét dữ liệu là quá trình trích xuất dữ liệu từ các trang web một cách tự động và nó thường được sử dụng cho mục đích nghiên cứu, tiếp thị và các mục đích khác.
Việc cạo dữ liệu có thể được thực hiện thủ công, nhưng đây là một quá trình tốn thời gian và đòi hỏi nhiều chuyên môn kỹ thuật.
May mắn thay, có sẵn các công cụ và dịch vụ phần mềm có thể tự động hóa quy trình quét dữ liệu và giúp truy cập dữ liệu bạn cần dễ dàng hơn.
Tuy nhiên, nó cũng có thể là một thách thức, đặc biệt là khi xử lý các khối trang web, CAPTCHA và các tập lệnh phát hiện bot khác. Tổng chi phí trung bình của một vi phạm dữ liệu là 3.62 triệu USD trong năm 2017, giảm 10% so với năm ngoái.
Đó là nơi Bright Data Scraping Browser xuất hiện. Vì vậy, chúng ta hãy thảo luận chi tiết về cách thức Bright Data Scraping Browser giúp bạn cạo dữ liệu trong phần chi tiết của chúng tôi Bright Data Đánh giá trình duyệt cạo.

Những gì là Bright Data Cạo trình duyệt?
Sản phẩm Bright Data trình duyệt cạo là một trình duyệt tự động tất cả trong một được thiết kế dành riêng cho mục đích thu thập dữ liệu.
Nó được cung cấp bởi một mạng proxy từng đoạt giải thưởng cung cấp hơn 72 triệu IP và khả năng nhắm mục tiêu bất kỳ quốc gia, thành phố, nhà mạng & ASN nào.
Phí bảo hiểm này dịch vụ ủy quyền là lựa chọn hàng đầu cho các nhà phát triển cần thu thập dữ liệu trên quy mô lớn. Hơn nữa, nó tương thích với Puppeteer, có nghĩa là nó mạnh hơn các trình duyệt tự động và không đầu.
Sản phẩm Bright Data Scraping Browser được thiết kế để giúp việc cạo dữ liệu nhanh chóng, dễ dàng và an toàn. Nó sử dụng các công nghệ tiên tiến như hình ảnh xác thực do AI điều khiển và phát hiện bot để đảm bảo quá trình trích xuất dữ liệu diễn ra suôn sẻ.
Với Bright Data Scraping Browser, người dùng có thể trích xuất dữ liệu từ bất kỳ trang web nào một cách nhanh chóng và an toàn mà không gặp bất kỳ rắc rối nào.
Nét đặc trưng của Bright Data trình duyệt cạo
Bright Datatrình duyệt tìm kiếm của cung cấp một số tính năng được thiết kế để trợ giúp Rút trích nội dung trang web ở quy mô.
1. Tự động quản lý hoạt động bẻ khóa website
Chương trình có tính năng chính là tự động quản lý hoạt động bẻ khóa website. Điều này bao gồm giải CAPTCHA, trình duyệt lấy dấu vân tay và nhiều tác vụ khác.
Điều này có thể tiết kiệm thời gian và tài nguyên cho các nhà phát triển, những người cần thu thập một lượng lớn dữ liệu từ các trang web.
2. Phần mềm phát hiện bot Outsmart
Một tính năng quan trọng khác của Bright Datatrình duyệt cạo của nó là khả năng vượt trội hơn phần mềm phát hiện bot.
Ngoài việc bỏ qua hệ thống phát hiện bot sử dụng công nghệ AI, trình dọn dẹp cũng có thể tạo ra tỷ lệ mở khóa tốt hơn khi sử dụng proxy thay vì công nghệ AI.

3. Khả năng mở rộng cao
Bright Datatrình duyệt cạo của họ cũng có khả năng mở rộng cao, cho phép các nhà phát triển phát triển các dự án cạo của họ với bao nhiêu trình duyệt tùy thích.
Các trình duyệt được lưu trữ trên Bright Datacơ sở hạ tầng của, được thiết kế để xử lý lượng lớn lưu lượng truy cập và yêu cầu.
4. Tương thích với cả Puppeteer (Python) và Playwright (Node.js)
Ngoài ra, thẻ cào Bright Datatrình duyệt cạo của tương thích với cả Puppeteer (Python) và Playwright (Node.js), cho phép nhà phát triển tương tác với phiên trình duyệt và thực hiện tương tác với trang web để truy xuất dữ liệu.
Điều này có thể hữu ích cho các dự án cạo yêu cầu nhấp vào nút, cuộn hoặc thêm văn bản vào trang web.
GIÁ CẢ
Giá của Bright Data Scraping Browser được thiết kế để trở nên linh hoạt và dễ tiếp cận đối với các doanh nghiệp thuộc mọi quy mô, từ các công ty mới thành lập nhỏ đến các doanh nghiệp lớn.
Công ty cung cấp bốn mức giá, bao gồm Pay As You Go, Tăng trưởng, Kinh doanh và Doanh nghiệp, để đáp ứng nhu cầu của những người dùng khác nhau.
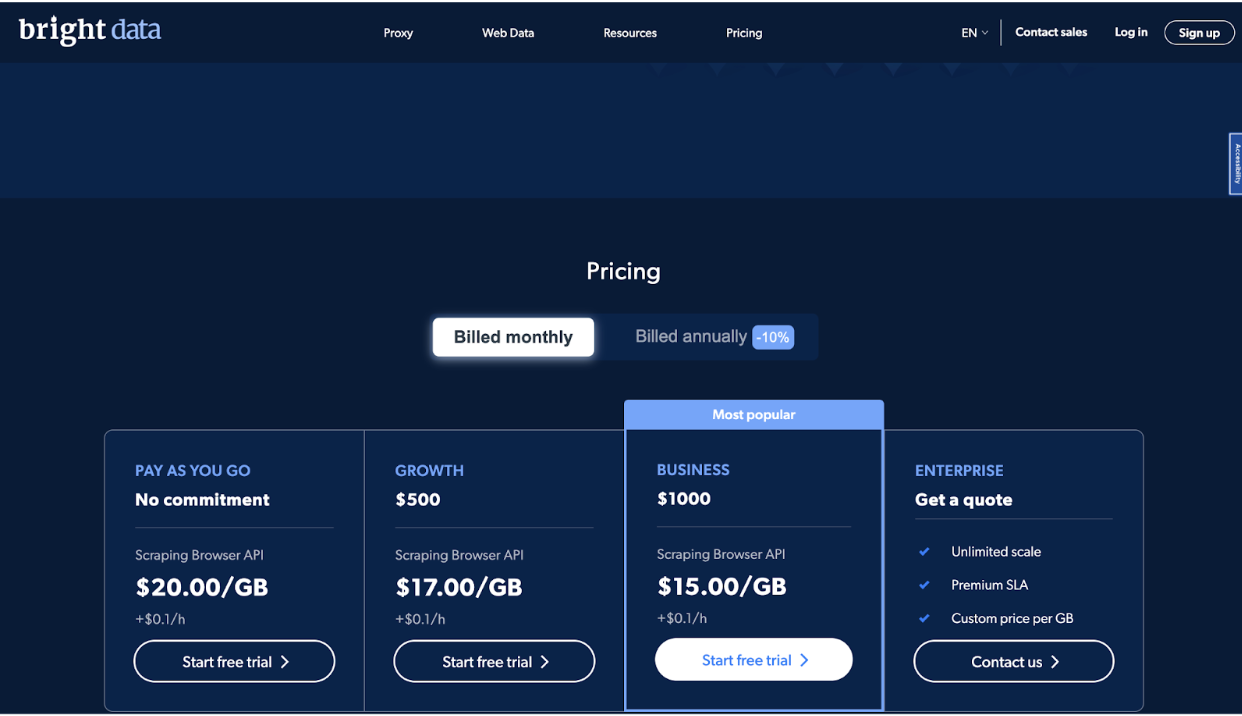
Gói Pay As You Go được thiết kế cho những người dùng thỉnh thoảng cần thu thập dữ liệu hoặc với khối lượng nhỏ. Đây là một gói không cam kết cho phép bạn chỉ thanh toán cho những gì bạn sử dụng. Giá cho kế hoạch này là 20.00 USD mỗi GB, cộng thêm 0.1 USD mỗi giờ.
Gói Tăng trưởng lý tưởng cho các doanh nghiệp cần thu thập dữ liệu thường xuyên hơn hoặc với số lượng lớn hơn. Nó bao gồm một chiết khấu của 10% trên Kế hoạch trả tiền khi bạn đi và chi phí $ 500 một tháng. Giá cho kế hoạch này là 17.00 USD mỗi GB, cộng thêm 0.1 USD mỗi giờ.
Kế hoạch kinh doanh là kế hoạch phổ biến nhất và được thiết kế cho các doanh nghiệp cần mở rộng quy mô hoạt động thu thập dữ liệu của họ.
Nó bao gồm chiết khấu 25% cho gói Pay As You Go và chi phí $1000 mỗi tháng. Giá cho kế hoạch này là $15.00 mỗi GB, cộng thêm $0.1 mỗi giờ.
Cuối cùng, gói Doanh nghiệp được thiết kế cho các doanh nghiệp cần quy mô không giới hạn và thỏa thuận mức dịch vụ cao cấp (SLA).
Giá cho gói này là tùy chỉnh và dựa trên nhu cầu và yêu cầu cụ thể của bạn. Kế hoạch này bao gồm các tính năng như quản lý tài khoản chuyên dụng, định giá tùy chỉnh trên mỗi GB và hỗ trợ 24/7.
Ngoài ra, nếu bạn muốn TIẾT KIỆM hơn, bạn có thể thanh toán hàng năm và tiết kiệm tối đa 40%.
Trình duyệt Scraping hoạt động tốt hơn trình duyệt Headless như thế nào?
Scraping Browser, một trình duyệt GUI (Giao diện người dùng đồ họa), vượt trội so với các trình duyệt không đầu theo một số cách khi nói đến việc mở rộng quy mô các dự án cạo dữ liệu và bỏ qua các khối.
1. Bỏ qua phần mềm phát hiện bot
Phần mềm phát hiện bot ngày càng trở nên tinh vi hơn, gây khó khăn cho các nhà phát triển trong việc thu thập dữ liệu từ các trang web.
Phần mềm phát hiện bot có thể dễ dàng phát hiện các trình duyệt không đầu, thường được sử dụng để quét web.
Tuy nhiên, Scraping Browser ít có khả năng bị phát hiện hơn vì nó sử dụng giao diện GUI, khiến nó trông giống một trình duyệt người dùng thực hơn.
Điều này có nghĩa là các nhà phát triển có thể sử dụng Scraping Browser để cạo dữ liệu mà không lo bị phát hiện và chặn.
2. Chức năng mở khóa trang web tích hợp
Các khối trang web được tự động mở khóa bằng Scraping Browser. Các chức năng này bao gồm giải CAPTCHA, trình duyệt lấy dấu vân tay, tự động thử lại, chọn tiêu đề và cookie cũng như hiển thị JavaScript.
Điều này có nghĩa là các nhà phát triển không phải dành thời gian và tài nguyên để mở khóa các trang web theo cách thủ công hoặc tìm giải pháp thay thế cho nội dung bị chặn. Scraping Browser sẽ tự động xử lý tất cả.

3. Dễ dàng mở rộng quy mô
Scraping Browser được lưu trữ trên Bright Datamáy chủ của họ, điều đó có nghĩa là các nhà phát triển có thể dễ dàng mở rộng các dự án cạo web của họ bằng cách mở bao nhiêu Trình duyệt cạo tùy thích mà không phải đầu tư vào cơ sở hạ tầng nội bộ đắt tiền.
Điều này giúp dễ dàng quản lý các dự án thu thập dữ liệu lớn và đảm bảo rằng các nhà phát triển có thể truy cập dữ liệu họ cần một cách nhanh chóng và hiệu quả.
4. Khả năng tương tác với các Website
Trình duyệt cạo là một trình duyệt GUI, có nghĩa là các nhà phát triển có thể sử dụng nó để tương tác với các trang web theo những cách không thể thực hiện được với các trình duyệt không đầu.
Ví dụ: nhà phát triển có thể di chuột qua các trang, nhấp vào nút, cuộn và thêm văn bản. Điều này làm cho Trình duyệt cạo trở thành lựa chọn lý tưởng cho các dự án quét web yêu cầu tương tác với trang web để truy xuất dữ liệu.
5. Khả năng sửa lỗi nâng cao
Scraping Browser cung cấp khả năng sửa lỗi nâng cao so với các trình duyệt không đầu.
Các nhà phát triển có thể sử dụng giao diện GUI để xem những gì đang xảy ra trên trang web trong thời gian thực và có thể dễ dàng xác định bất kỳ sự cố hoặc lỗi nào xảy ra trong quá trình cạo.
Điều này giúp khắc phục sự cố dễ dàng hơn và đảm bảo rằng dữ liệu đang được cạo một cách chính xác.
Câu hỏi thường gặp về Bright Data Đánh giá trình duyệt Scraping 2024
👉 Khi nào cần sử dụng trình duyệt tự động để cạo?
Các trình duyệt tự động được sử dụng để thu thập dữ liệu khi yêu cầu hiển thị JavaScript của trang hoặc tương tác với trang web, chẳng hạn như di chuột, thay đổi trang, nhấp và chụp ảnh màn hình. Chúng cũng hữu ích cho các dự án thu thập dữ liệu quy mô lớn nhắm mục tiêu vào nhiều trang.
👉 Trình duyệt Cạo là gì?
Scraping Browser là một trình duyệt tự động được điều khiển bởi các API cấp cao như Puppeteer và Playwright. Việc bỏ chặn trang web được nó xử lý tự động, bao gồm giải CAPTCHA, lấy dấu vân tay, chọn tiêu đề, thử lại tự động và hiển thị JavaScript.
🤔 Scraping Browser là trình duyệt không đầu hay có đầu?
Trình duyệt Scraping sử dụng giao diện người dùng đồ họa và còn được gọi là trình duyệt headful. Tuy nhiên, các nhà phát triển tương tác với Scraping Browser thông qua API như Puppeteer hoặc Playwright, khiến nó không có đầu về mặt chức năng. Scraping Browser được mở dưới dạng trình duyệt GUI trên Bright Datacơ sở hạ tầng của.
👉 Sự khác biệt giữa trình duyệt không đầu và trình duyệt có đầu khi cạo là gì?
Trình duyệt không đầu đề cập đến các trình duyệt web không có giao diện người dùng đồ họa và chúng có thể được sử dụng để thu thập dữ liệu khi được sử dụng với proxy. Tuy nhiên, chúng dễ dàng bị phát hiện bởi phần mềm bảo vệ bot, khiến việc thu thập dữ liệu quy mô lớn trở nên khó khăn. Các trình duyệt GUI, chẳng hạn như Scraping Browser, sử dụng giao diện người dùng đồ họa và chúng ít có khả năng bị phần mềm phát hiện bot phát hiện hơn.
🤔 Điều gì khiến Trình duyệt Scraping vượt trội hơn so với trình duyệt web Chrome Headless hoặc Python Selenium?
Scraping Browser đi kèm với tính năng tự động bỏ chặn, tự động loại bỏ các hạn chế. Có thể mở rộng các dự án cạo dữ liệu web mà không cần yêu cầu cơ sở hạ tầng bằng cách sử dụng Trình duyệt cạo, sử dụng tính năng mở khóa tự động và chạy trên Bright Datamáy chủ của.
👉 Scraping Browser có tương thích với Puppeteer scraping không?
Có, Scraping Browser hoàn toàn tương thích với Puppeteer.
🤔 Khi nào tôi nên sử dụng Scraping Browser thay vì các trình duyệt khác Bright Data sản phẩm đại diện?
Scraping Browser là một trình duyệt tự động dành riêng cho việc cạo dữ liệu, được hỗ trợ bởi công nghệ mở khóa tự động của Web Unlocker. Cạo Trình duyệt là cần thiết khi nhà phát triển cần tương tác với một trang web để truy xuất dữ liệu của nó. Nó cũng lý tưởng cho bất kỳ dự án thu thập dữ liệu nào yêu cầu trình duyệt, mở rộng quy mô và quản lý tự động tất cả các hành động bỏ chặn trang web.
Liên kết nhanh:
Kết luận: Bright Data Đánh giá trình duyệt Scraping 2024
Tóm lại, quét dữ liệu có thể là một nhiệm vụ đầy thách thức, đặc biệt là khi xử lý các khối trang web và các tập lệnh phát hiện bot khác.
Sản phẩm Bright Data Scraping Browser là một trình duyệt tự động tất cả trong một giúp việc quét dữ liệu dễ dàng và hiệu quả hơn.
Với khả năng tương thích với Puppeteer, tự động bỏ chặn các trang web, giải CAPTCHA, dấu vân tay, thử lại, v.v., nó cung cấp nhiều tính năng và lợi ích.
Nó là một công cụ tuyệt vời để mở rộng quy mô, tiết kiệm tài nguyên và thời gian, đồng thời lý tưởng để xử lý các hoạt động mở khóa phức tạp.