Caut un detaliat Bright Data Scraping Browser Review, Nu-ți face griji, te-am acoperit.
Internetul este un bazin enorm de date care poate fi incredibil de valoros pentru companii, cercetători și persoane fizice. Cu toate acestea, accesarea acestor date poate fi o sarcină descurajantă, mai ales când vine vorba de data scraping.
Data scraping este procesul de extragere automată a datelor de pe site-uri web și este adesea folosit pentru cercetare, marketing și alte scopuri.
Scrapingul datelor se poate face manual, dar acesta este un proces care consumă timp și necesită multă experiență tehnică.
Din fericire, există instrumente software și servicii disponibile care pot automatiza procesul de scraping a datelor și ușurează accesul la datele de care aveți nevoie.
Dar, poate fi și o provocare, mai ales atunci când aveți de-a face cu blocuri de site, CAPTCHA și alte scripturi de detectare a botului. Costul total mediu al unei breșe de date este de 3.62 milioane USD în 2017, o scădere cu 10% față de anul trecut.
Acolo este Bright Data Scraping Browser intră. Deci, haideți să discutăm în detaliu despre cum Bright Data Scraping Browser vă ajută la scraping-ul de date în detaliile noastre Bright Data Examinare a browserului Scraping.

Ce este Bright Data Scraping Browser?
Bright Data Scraping Browser este un browser automat, all-in-one, conceput special pentru colectarea datelor.
Este alimentat de o rețea proxy premiată care oferă peste 72 de milioane de IP-uri și capacitatea de a viza orice țară, oraș, operator de transport și ASN.
Această primă serviciu de proxy este o alegere de top pentru dezvoltatorii care au nevoie să curețe date la scară. În plus, este compatibil Puppeteer, ceea ce înseamnă că este mai puternic decât browserele automate și fără cap.
Bright Data Scraping Browser este conceput pentru a face scrapingul de date rapid, ușor și sigur. Utilizează tehnologii avansate, cum ar fi captcha bazată pe inteligență artificială și detectarea botului, care asigură extragerea fără probleme a datelor.
Cu Bright Data Scraping Browser, utilizatorii pot extrage rapid și în siguranță date de pe orice site web, fără nicio bătaie de cap.
caracteristici ale Bright Data Scraping Browser
Bright DataBrowserul de scraping al lui oferă o serie de caracteristici concepute pentru a ajuta Răzuire web la scară.
1. Gestionarea automată a operațiunilor de deblocare a site-ului web
Programul are o caracteristică cheie de gestionare automată a operațiunilor de deblocare a site-ului web. Aceasta include rezolvarea de CAPTCHA, browserele de amprentă și o varietate de alte sarcini.
Acest lucru poate economisi timp și resurse pentru dezvoltatorii care trebuie să colecteze cantități mari de date de pe site-uri web.
2. Depășește software-ul de detectare a bot-ului
O altă caracteristică importantă a Bright DataBrowserul de scraping al lui este capacitatea sa de a depăși software-ul de detectare a bot-ului.
Pe lângă ocolire sisteme de detectare a botului folosind tehnologia AI, scraper-urile pot produce, de asemenea, rate de deblocare mai bune atunci când folosesc proxy în loc de tehnologia AI.

3. Foarte scalabil
Bright DataBrowserul de scraping al lui este, de asemenea, foarte scalabil, permițând dezvoltatorilor să-și dezvolte proiectele de scraping cu câte browsere au nevoie.
Browserele sunt găzduite pe Bright Datainfrastructura lui, care este concepută pentru a gestiona cantități mari de trafic și solicitări.
4. Compatibil atât cu Puppeteer (Python) cât și cu Dramaturg (Node.js)
În cele din urmă, Bright DataBrowserul de scraping al lui este compatibil atât cu Puppeteer (Python) cât și cu Playwright (Node.js), ceea ce permite dezvoltatorilor să interacționeze cu sesiunile de browser și să efectueze interacțiuni cu site-ul web pentru a prelua date.
Acest lucru poate fi util pentru scraping proiecte care necesită clic pe butoane, defilare sau adăugare de text în paginile web.
Tarif
Prețul Bright Data Scraping Browser este proiectat pentru a fi flexibil și accesibil pentru companii de toate dimensiunile, de la startup-uri mici la întreprinderi mari.
Compania oferă patru niveluri de preț, inclusiv Pay As You Go, Growth, Business și Enterprise, pentru a satisface nevoile diferiților utilizatori.
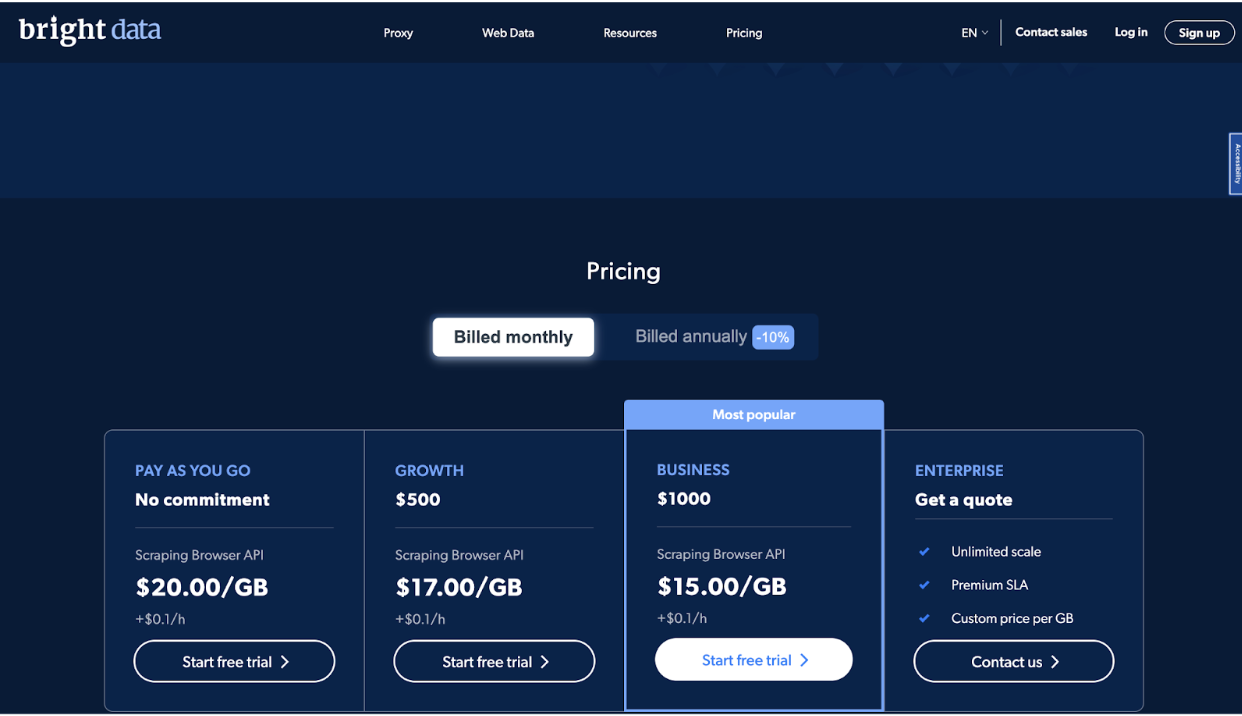
Planul Pay As You Go este conceput pentru utilizatorii care au nevoie să curețe date ocazional sau în volume mici. Este un plan fără angajamente care vă permite să plătiți doar pentru ceea ce utilizați. Prețul pentru acest plan este 20.00 USD per GB, plus 0.1 USD pe oră.
Planul de creștere este ideal pentru companiile care au nevoie să colecteze date mai frecvent sau în volume mai mari. Include a reducere de 10% pe Planul Pay As You Go si costuri 500 $ pe lună. Prețul pentru acest plan este 17.00 USD per GB, plus 0.1 USD pe oră.
Planul de afaceri este cel mai popular plan și este conceput pentru companiile care trebuie să-și extindă operațiunile de colectare a datelor.
Include o reducere de 25% la planul Pay As You Go și costă 1000 USD pe lună. Prețul pentru acest plan este 15.00 USD per GB, plus 0.1 USD pe oră.
În cele din urmă, planul Enterprise este conceput pentru companiile care au nevoie de o scară nelimitată și a acord de nivel de servicii premium (SLA).
Prețul pentru acest plan este personalizat și se bazează pe nevoile și cerințele dumneavoastră specifice. Acest plan include funcții precum management dedicat contului, prețuri personalizate pe GB și asistență 24/7.
De asemenea, dacă doriți să economisiți mai mult, puteți plăti anual și salvați până la 40%.
Cum Scraping Browsere depășește browserele Headless?
Scraping Browser, un browser GUI (Graphical User Interface), depășește browserele fără cap în mai multe moduri atunci când vine vorba de scalarea proiectelor de scraping de date și de ocolire a blocurilor.
1. Ocolirea software-ului de detectare a botului
Software-ul de detectare a boturilor devine din ce în ce mai sofisticat, ceea ce face dificil pentru dezvoltatori să răzuiască datele de pe site-uri web.
Software-ul de detectare a botului este capabil să detecteze cu ușurință browserele fără cap, care sunt utilizate în mod obișnuit pentru a răzui web-ul.
Cu toate acestea, Scraping Browser este mai puțin probabil să fie detectat, deoarece folosește o interfață GUI, ceea ce îl face să pară mai mult ca un browser de utilizator real.
Aceasta înseamnă că dezvoltatorii pot folosi Scraping Browser pentru a răzui datele fără a-și face griji că sunt detectați și blocați.
2. Funcții de deblocare a site-ului web încorporate
Blocurile site-urilor web sunt deblocate automat de Scraping Browser. Aceste funcții includ rezolvarea CAPTCHA-urilor, amprentarea browserelor, reîncercarea automată, selectarea antetelor și cookie-urilor și redarea JavaScript.
Aceasta înseamnă că dezvoltatorii nu trebuie să cheltuiască timp și resurse pentru a debloca manual site-urile web sau pentru a găsi soluții pentru conținutul blocat. Scraping Browser se ocupă de totul automat.

3. Ușor de scalat
Scraping Browser este găzduit pe Bright Dataserverele lui, ceea ce înseamnă că dezvoltatorii își pot scala cu ușurință proiectele de web scraping deschizând câte browsere Scraping au nevoie, fără a fi nevoiți să investească în infrastructura internă costisitoare.
Acest lucru facilitează gestionarea proiectelor mari de date scraping și asigură că dezvoltatorii pot accesa datele de care au nevoie rapid și eficient.
4. Abilitatea de a interacționa cu site-urile web
Un browser scraping este un browser GUI, ceea ce înseamnă că dezvoltatorii îl pot folosi pentru a interacționa cu site-urile web în moduri care nu sunt posibile cu browserele fără cap.
De exemplu, dezvoltatorii pot trece cu mouse-ul peste pagini, pot face clic pe butoane, pot derula și pot adăuga text. Acest lucru face din Browserul Scraping o alegere ideală pentru proiectele de web scraping care necesită interacțiuni cu site-ul web pentru a prelua date.
5. Capacități îmbunătățite de depanare
Scraping Browser oferă capabilități îmbunătățite de depanare în comparație cu browserele fără cap.
Dezvoltatorii pot folosi interfața GUI pentru a vedea ce se întâmplă pe site-ul web în timp real și pot identifica cu ușurință orice probleme sau erori care apar în timpul procesului de scraping.
Acest lucru facilitează depanarea problemelor și vă asigură că datele sunt răzuite corect.
Întrebări frecvente pornite Bright Data Scraping Browser Review 2024
👉 Când este necesar să folosiți un browser automat pentru scraping?
Browserele automate sunt folosite pentru colectarea datelor atunci când este necesară redarea JavaScript a unei pagini sau interacțiunile cu un site web, cum ar fi trecerea cu mouse-ul, schimbarea paginilor, clicurile și realizarea de capturi de ecran. Ele sunt, de asemenea, utile pentru proiecte de scraping de date la scară largă care vizează mai multe pagini.
👉 Ce este Scraping Browser?
Scraping Browser este un browser automat controlat de API-uri de nivel înalt, cum ar fi Puppeteer și Playwright. Deblocarea site-ului web este gestionată automat sub capotă de către acesta, inclusiv rezolvarea CAPTCHA, amprentarea, selecția antetului, reîncercări automate și redarea JavaScript.
🤔 Scraping Browser este un browser fără cap sau cu cap?
Browserul Scraping folosește o interfață grafică cu utilizatorul și este numit și browser headful. Cu toate acestea, dezvoltatorii interacționează cu Scraping Browser printr-un API precum Puppeteer sau Playwright, făcându-l funcțional fără cap. Scraping Browser este deschis ca browser GUI Bright Datainfrastructura lui.
👉 Care este diferența dintre un browser fără cap și un browser cu cap când vine vorba de scraping?
Browserele fără cap se referă la browsere web fără o interfață grafică de utilizator și pot fi folosite pentru a răzui date atunci când sunt utilizate cu un proxy. Cu toate acestea, ele sunt ușor de detectat de software-ul de protecție împotriva botului, ceea ce face dificilă scrapingul pe scară largă a datelor. Browserele GUI, cum ar fi Scraping Browser, folosesc o interfață grafică cu utilizatorul și este mai puțin probabil ca acestea să fie detectate de software-ul de detectare a botului.
🤔 Ce face Scraping Browser superior scraping-ului web Chrome Headless sau Python Selenium?
Scraping Browser vine cu o funcție de deblocare automată care elimină automat restricțiile. Este posibil să scalați proiectele de scraping de date web fără cerințe de infrastructură utilizând Scraping Browser, care utilizează deblocare automată și rulează pe Bright Dataserverele lui.
👉 Este Scraping Browser compatibil cu Puppeteer scraping?
Da, Scraping Browser este pe deplin compatibil cu Puppeteer.
🤔 Când ar trebui să folosesc Scraping Browser în loc de altul Bright Data produse proxy?
Scraping Browser este un browser automat dedicat scraping-ului de date, alimentat de tehnologia de deblocare automată a Web Unlocker. Scrapingul unui browser este necesar atunci când un dezvoltator trebuie să interacționeze cu un site web pentru a-și prelua datele. De asemenea, este ideal pentru orice proiect de scraping de date care necesită browsere, scalare și gestionarea automată a tuturor acțiunilor de deblocare a site-ului web.
Link-uri rapide:
Concluzie: Bright Data Scraping Browser Review 2024
În concluzie, data scraping poate fi o sarcină dificilă, mai ales atunci când aveți de-a face cu blocuri de site-uri web și alte scripturi de detectare a botului.
Bright Data Scraping Browser este un browser automat, all-in-one, care face scrapingul datelor mai ușor și mai eficient.
Cu compatibilitatea cu Puppeteer, deblocarea automată a site-urilor, rezolvarea CAPTCHA, amprentele digitale, reîncercări și multe altele, oferă o gamă largă de funcții și beneficii.
Este un instrument excelent pentru scalare, economisește resurse și timp și este ideal pentru gestionarea operațiunilor complexe de deblocare.