Procurando um detalhado Bright Data Raspando Revisão do Navegador, Não se preocupe, eu tenho você coberto.
A internet é um enorme conjunto de dados que pode ser incrivelmente valioso para empresas, pesquisadores e indivíduos. No entanto, acessar esses dados pode ser uma tarefa assustadora, especialmente quando se trata de extração de dados.
A raspagem de dados é o processo de extrair dados de sites automaticamente e é frequentemente usado para pesquisa, marketing e outros fins.
A raspagem de dados pode ser feita manualmente, mas é um processo demorado e requer muita experiência técnica.
Felizmente, existem ferramentas e serviços de software disponíveis que podem automatizar o processo de coleta de dados e facilitar o acesso aos dados de que você precisa.
Mas também pode ser desafiador, especialmente ao lidar com bloqueios de sites, CAPTCHA e outros scripts de detecção de bots. O custo total médio de uma violação de dados é de US$ 3.62 milhões em 2017, uma queda de 10% em relação ao ano passado.
É aí que o Bright Data Scraping Browser entra. Então, vamos discutir em detalhes sobre como o Bright Data O Scraping Browser ajuda você na extração de dados em nosso detalhado Bright Data Revisão do navegador de raspagem.

O que é Bright Data Navegador de raspagem?
A Bright Data Navegador de raspagem é um navegador automatizado completo projetado especificamente para fins de coleta de dados.
Ele é alimentado por uma rede proxy premiada que oferece mais de 72 milhões de IPs e a capacidade de segmentar qualquer país, cidade, operadora e ASN.
Este prêmio serviço de proxy é a melhor escolha para desenvolvedores que precisam coletar dados em grande escala. Além disso, é compatível com o Puppeteer, o que significa que é mais poderoso que os navegadores automatizados e sem cabeça.
A Bright Data O Scraping Browser foi projetado para tornar a raspagem de dados rápida, fácil e segura. Ele usa tecnologias avançadas, como captcha orientado por IA e detecção de bot, que garante uma extração de dados suave.
Com o Bright Data Scraping Browser, os usuários podem extrair dados de qualquer site com rapidez e segurança, sem complicações.
Características de Bright Data Navegador de raspagem
Bright DataO navegador de raspagem oferece vários recursos projetados para ajudar com Raspagem da web em escala.
1. Gerenciamento automático das operações de desbloqueio do site
O programa possui um recurso importante de gerenciamento automático de operações de desbloqueio de sites. Isso inclui a solução de CAPTCHAs, impressão digital de navegadores e uma variedade de outras tarefas.
Isso pode economizar tempo e recursos para desenvolvedores que precisam extrair grandes quantidades de dados de sites.
2. Outsmart software de detecção de bot
Outra característica importante do Bright DataO navegador de raspagem é sua capacidade de enganar o software de detecção de bots.
Além de contornar sistemas de detecção de bots usando a tecnologia AI, os scrapers também podem produzir melhores taxas de desbloqueio ao usar proxies em vez da tecnologia AI.

3. Altamente escalável
Bright DataO navegador de raspagem do também é altamente escalável, permitindo que os desenvolvedores aumentem seus projetos de raspagem com quantos navegadores precisarem.
Os navegadores são hospedados em Bright Datada infraestrutura, projetada para lidar com grandes quantidades de tráfego e solicitações.
4. Compatível com Puppeteer (Python) e Playwright (Node.js)
Finalmente, Bright DataO navegador de raspagem do é compatível com Puppeteer (Python) e Playwright (Node.js), o que permite que os desenvolvedores interajam com as sessões do navegador e realizem interações no site para recuperar dados.
Isso pode ser útil para raspar projetos que exijam clicar em botões, rolar ou adicionar texto a páginas da web.
Preços
O preço do Bright Data O Scraping Browser foi projetado para ser flexível e acessível a empresas de todos os tamanhos, desde pequenas startups até grandes empresas.
A empresa oferece quatro níveis de preços, incluindo Pay As You Go, Growth, Business e Enterprise, para atender às necessidades de diferentes usuários.
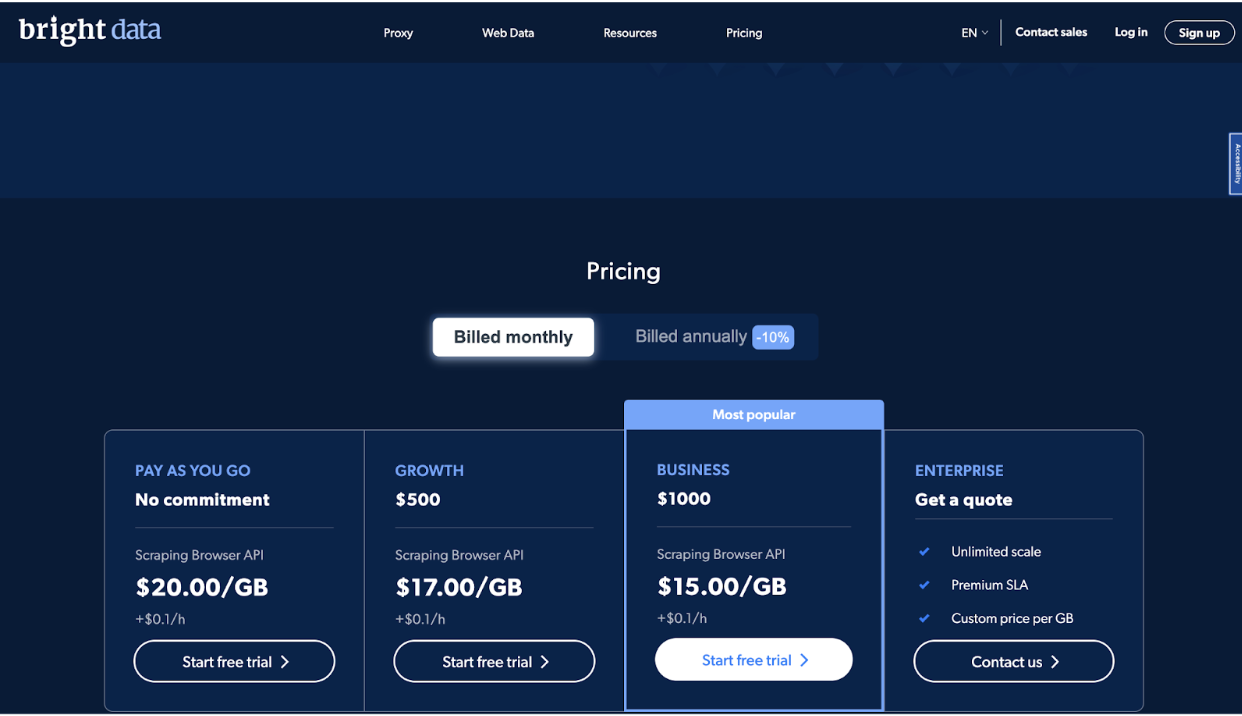
O plano Pay As You Go foi desenvolvido para usuários que precisam coletar dados ocasionalmente ou em pequenos volumes. É um plano sem compromisso que permite que você pague apenas pelo que usar. O preço para este plano é US$ 20.00 por GB, mais US$ 0.1 por hora.
O plano Growth é ideal para empresas que precisam coletar dados com mais frequência ou em volumes maiores. Inclui um desconto de 10% na Plano Pay As You Go e custos $ 500 por mês. O preço para este plano é US$ 17.00 por GB, mais US$ 0.1 por hora.
O plano Business é o plano mais popular e foi desenvolvido para empresas que precisam escalar suas operações de coleta de dados.
Inclui um desconto de 25% no plano Pay As You Go e custa $ 1000 por mês. O preço para este plano é US$ 15.00 por GB, mais US$ 0.1 por hora.
Por fim, o plano Enterprise foi desenvolvido para empresas que precisam de escala ilimitada e um contrato de nível de serviço premium (SLA).
O preço desse plano é personalizado e baseado em suas necessidades e requisitos específicos. Este plano inclui recursos como gerenciamento de conta dedicado, preços personalizados por GB e suporte 24 horas por dia, 7 dias por semana.
Além disso, se você deseja ECONOMIZAR mais, você pode pagar anualmente e economize até 40%.
Como os navegadores de raspagem superam os navegadores sem cabeça?
O Scraping Browser, um navegador GUI (Graphical User Interface), supera os navegadores sem cabeça de várias maneiras quando se trata de dimensionar projetos de raspagem de dados e contornar blocos.
1. Ignorando o Software de Detecção de Bots
O software de detecção de bots está se tornando cada vez mais sofisticado, tornando difícil para os desenvolvedores extrair dados de sites.
O software de detecção de bot é facilmente capaz de detectar navegadores sem cabeça, que são comumente usados para raspar a web.
No entanto, o Scraping Browser tem menos probabilidade de ser detectado porque usa uma interface GUI, o que o torna mais parecido com um navegador de usuário real.
Isso significa que os desenvolvedores podem usar o Scraping Browser para coletar dados sem se preocupar em serem detectados e bloqueados.
2. Funções integradas de desbloqueio do site
Os bloqueios de sites são desbloqueados automaticamente pelo Scraping Browser. Essas funções incluem a resolução de CAPTCHAs, impressões digitais de navegadores, novas tentativas automáticas, seleção de cabeçalhos e cookies e renderização de JavaScript.
Isso significa que os desenvolvedores não precisam gastar tempo e recursos para desbloquear sites manualmente ou encontrar soluções alternativas para conteúdo bloqueado. Scraping Browser cuida de tudo automaticamente.

3. Fácil de dimensionar
O Scraping Browser está hospedado em Bright Data's, o que significa que os desenvolvedores podem escalar facilmente seus projetos de raspagem na web abrindo quantos navegadores de raspagem forem necessários, sem ter que investir em infraestrutura interna cara.
Isso facilita o gerenciamento de grandes projetos de coleta de dados e garante que os desenvolvedores possam acessar os dados de que precisam com rapidez e eficiência.
4. Capacidade de interagir com sites
Um navegador de raspagem é um navegador GUI, o que significa que os desenvolvedores podem usá-lo para interagir com sites de maneiras que não são possíveis com navegadores sem cabeça.
Por exemplo, os desenvolvedores podem passar o mouse sobre as páginas, clicar em botões, rolar e adicionar texto. Isso torna o Scraping Browser uma escolha ideal para projetos de web scraping que exigem interações com o site para recuperar dados.
5. Recursos aprimorados de depuração
O Scraping Browser fornece recursos de depuração aprimorados em comparação com os navegadores sem cabeça.
Os desenvolvedores podem usar a interface GUI para ver o que está acontecendo no site em tempo real e podem identificar facilmente quaisquer problemas ou erros que ocorram durante o processo de extração.
Isso facilita a solução de problemas e garante que os dados sejam extraídos corretamente.
Perguntas frequentes sobre Bright Data Revisão do navegador de raspagem 2024
👉 Quando é necessário usar um navegador automatizado para raspagem?
Navegadores automatizados são usados para coleta de dados quando a renderização de JavaScript de uma página ou interações com um site são necessárias, como passar o mouse, alterar páginas, clicar e tirar capturas de tela. Eles também são úteis para projetos de coleta de dados em grande escala direcionados a várias páginas.
👉 O que é Scraping Browser?
Scraping Browser é um navegador automatizado controlado por APIs de alto nível, como Puppeteer e Playwright. O desbloqueio do site é feito automaticamente por ele, incluindo resolução de CAPTCHA, impressão digital, seleção de cabeçalho, novas tentativas automáticas e renderização de JavaScript.
🤔 O Scraping Browser é um navegador headless ou headful?
O Scraping Browser usa uma interface gráfica do usuário e também é chamado de headful browser. No entanto, os desenvolvedores interagem com o Scraping Browser por meio de uma API como Puppeteer ou Playwright, tornando-o funcionalmente sem comando. Scraping Browser é aberto como um navegador GUI em Bright Datada infraestrutura.
👉 Qual é a diferença entre um navegador headless e headful quando se trata de scraping?
Os navegadores sem cabeça referem-se a navegadores da Web sem uma interface gráfica do usuário e podem ser usados para coletar dados quando usados com um proxy. No entanto, eles são facilmente detectados pelo software de proteção de bots, dificultando a extração de dados em grande escala. Os navegadores GUI, como o Scraping Browser, usam uma interface gráfica do usuário e têm menos probabilidade de serem detectados pelo software de detecção de bot.
🤔 O que torna o Scraping Browser superior ao Chrome Headless ou Python Selenium web scraping?
O Scraping Browser vem com um recurso de desbloqueio automático que remove automaticamente as restrições. É possível dimensionar projetos de extração de dados da Web sem requisitos de infraestrutura usando Scraping Browsers, que empregam desbloqueio automatizado e são executados em Bright Dataservidores.
👉 O Scraping Browser é compatível com a raspagem do Puppeteer?
Sim, o Scraping Browser é totalmente compatível com o Puppeteer.
🤔 Quando devo usar o Scraping Browser em vez de outro Bright Data produtos proxy?
Scraping Browser é um navegador automatizado dedicado a raspagem de dados, alimentado pela tecnologia de desbloqueio automatizado do Web Unlocker. A raspagem de um navegador é necessária quando um desenvolvedor precisa interagir com um site para recuperar seus dados. Também é ideal para qualquer projeto de coleta de dados que exija navegadores, dimensionamento e gerenciamento automatizado de todas as ações de desbloqueio do site.
Links Rápidos:
Conclusão: Bright Data Revisão do navegador de raspagem 2024
Concluindo, a extração de dados pode ser uma tarefa desafiadora, especialmente ao lidar com bloqueios de sites e outros scripts de detecção de bots.
A Bright Data Scraping Browser é um navegador automatizado completo que torna a raspagem de dados mais fácil e eficiente.
Com compatibilidade com Puppeteer, desbloqueio automático de sites, resolução CAPTCHA, impressões digitais, novas tentativas e muito mais, ele oferece uma ampla gama de recursos e benefícios.
É uma excelente ferramenta para dimensionamento, economiza recursos e tempo e é ideal para lidar com operações complexas de desbloqueio.