Szukasz szczegółowego Bright Data Skrobanie recenzji przeglądarki, Nie martw się, zapewniam cię.
Internet to ogromna pula danych, które mogą być niezwykle cenne dla firm, badaczy i osób prywatnych. Jednak dostęp do tych danych może być zniechęcającym zadaniem, zwłaszcza jeśli chodzi o skrobanie danych.
Zbieranie danych to proces automatycznego wydobywania danych ze stron internetowych, często wykorzystywany do celów badawczych, marketingowych i innych.
Skrobanie danych można wykonać ręcznie, ale jest to proces czasochłonny i wymagający dużej wiedzy technicznej.
Na szczęście dostępne są narzędzia programowe i usługi, które mogą zautomatyzować proces zbierania danych i ułatwić dostęp do potrzebnych danych.
Ale może to być również trudne, zwłaszcza w przypadku blokad witryn, CAPTCHA i innych skryptów wykrywających boty. Średni całkowity koszt naruszenia ochrony danych wyniósł 3.62 mln USD w 2017 r., co oznacza spadek o 10 procent w porównaniu z ubiegłym rokiem.
Tam właśnie jest Bright Data Pojawia się przeglądarka Scraping Browser. Omówmy więc szczegółowo, w jaki sposób Bright Data Scraping Browser pomaga w zgarnianiu danych w naszym szczegółowym Bright Data Recenzja przeglądarki Scraping.

Co jest Bright Data Skrobanie przeglądarki?
Połączenia Bright Data Skrobanie przeglądarki to wszechstronna zautomatyzowana przeglądarka zaprojektowana specjalnie do zbierania danych.
Jest zasilany przez wielokrotnie nagradzaną sieć proxy, która oferuje ponad 72 miliony adresów IP oraz możliwość kierowania na dowolny kraj, miasto, przewoźnika i ASN.
Ta premia usługa proxy to najlepszy wybór dla programistów, którzy muszą zbierać dane na dużą skalę. Co więcej, jest kompatybilny z Puppeteer, co oznacza, że jest potężniejszy niż zautomatyzowane i bezgłowe przeglądarki.
Połączenia Bright Data Scraping Browser został zaprojektowany tak, aby usuwanie danych było szybkie, łatwe i bezpieczne. Wykorzystuje zaawansowane technologie, takie jak wykrywanie captcha i botów oparte na sztucznej inteligencji, które zapewniają płynną ekstrakcję danych.
Z Bright Data Scraping Browser, użytkownicy mogą szybko i bezpiecznie wyodrębnić dane z dowolnej witryny bez żadnych problemów.
Cechy Bright Data Skrobanie przeglądarki
Bright DataPrzeglądarka do skrobania oferuje szereg funkcji zaprojektowanych z myślą o pomocy Skrobanie stron internetowych na wadze.
1. Automatyczne zarządzanie operacjami odblokowywania stron internetowych
Program posiada kluczową funkcję automatycznego zarządzania operacjami odblokowywania stron internetowych. Obejmuje to rozwiązywanie CAPTCHA, pobieranie odcisków palców przeglądarek i wiele innych zadań.
Może to zaoszczędzić czas i zasoby dla programistów, którzy muszą zeskrobać duże ilości danych ze stron internetowych.
2. Przechytrz oprogramowanie do wykrywania botów
Kolejna ważna cecha Bright DataPrzeglądarka skrobająca to jej zdolność do przechytrzenia oprogramowania do wykrywania botów.
Oprócz omijania systemy wykrywania botów korzystając z technologii AI, skrobaki mogą również generować lepsze szybkości odblokowywania przy użyciu serwerów proxy zamiast technologii AI.

3. Wysoce skalowalny
Bright DataPrzeglądarka skrobania jest również wysoce skalowalna, umożliwiając programistom rozwijanie projektów skrobania za pomocą dowolnej liczby przeglądarek.
Przeglądarki są hostowane na Bright Datainfrastruktury firmy, która jest zaprojektowana do obsługi dużych ilości ruchu i żądań.
4. Kompatybilny zarówno z Puppeteer (Python), jak i Playwright (Node.js)
Wreszcie, Bright DataPrzeglądarka skrobająca jest kompatybilna zarówno z Puppeteer (Python), jak i Playwright (Node.js), co pozwala programistom na interakcję z sesjami przeglądarki i wykonywanie interakcji w witrynie w celu pobierania danych.
Może to być przydatne w przypadku projektów, które wymagają klikania przycisków, przewijania lub dodawania tekstu do stron internetowych.
Cennik
Cena Bright Data Przeglądarka Scraping została zaprojektowana tak, aby była elastyczna i dostępna dla firm każdej wielkości, od małych startupów po duże przedsiębiorstwa.
Firma oferuje cztery poziomy cen, w tym Pay As You Go, Growth, Business i Enterprise, aby zaspokoić potrzeby różnych użytkowników.
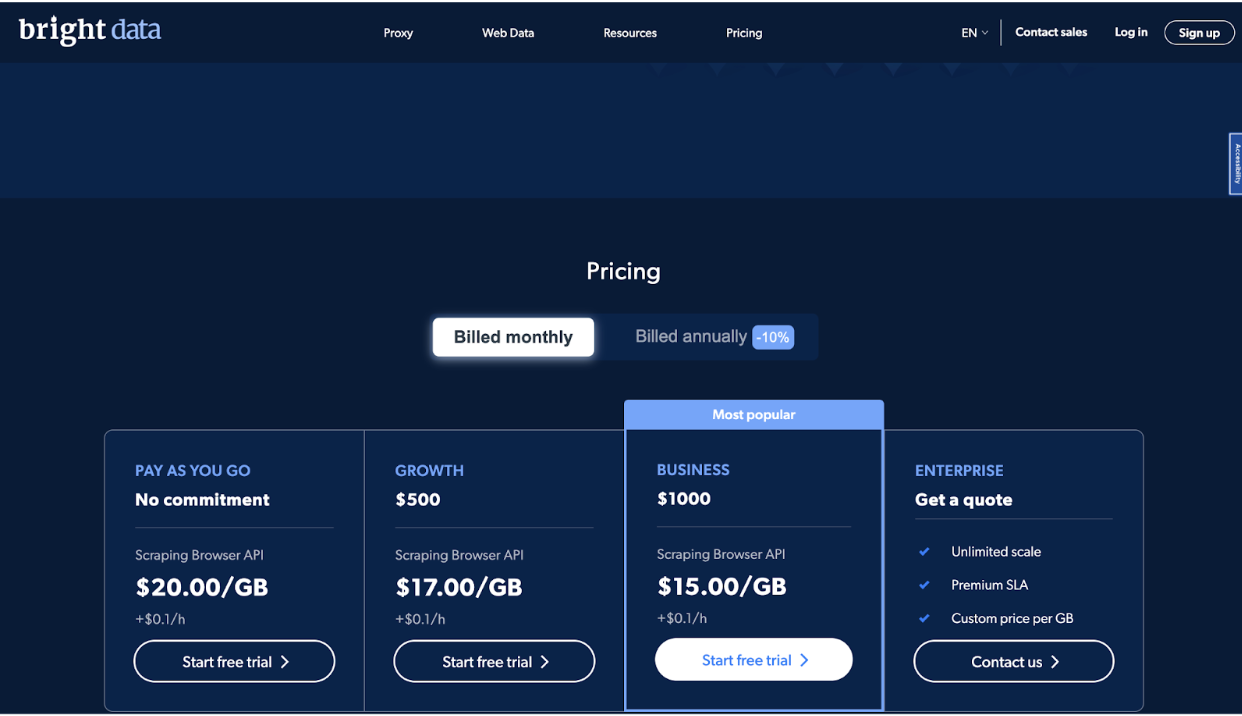
Plan Pay As You Go jest przeznaczony dla użytkowników, którzy od czasu do czasu lub w małych ilościach muszą zbierać dane. Jest to plan bez zobowiązań, który pozwala płacić tylko za to, z czego korzystasz. Cena tego planu to 20.00 USD za GB plus 0.1 USD za godzinę.
Plan wzrostu jest idealny dla firm, które muszą zbierać dane częściej lub w większych ilościach. Zawiera zniżka 10% na Plan płatności zgodnie z rzeczywistym użyciem i koszty $ 500 za miesiąc. Cena tego planu to 17.00 USD za GB plus 0.1 USD za godzinę.
Plan biznesowy jest najpopularniejszym planem i jest przeznaczony dla firm, które muszą skalować swoje operacje zbierania danych.
Obejmuje zniżkę w wysokości 25% na plan Pay As You Go i kosztuje 1000 USD miesięcznie. Cena tego planu to 15.00 USD za GB plus 0.1 USD za godzinę.
Wreszcie, plan Enterprise jest przeznaczony dla firm, które potrzebują nieograniczonej skali i umowa o poziomie usług premium (SLA).
Ceny tego planu są niestandardowe i oparte na konkretnych potrzebach i wymaganiach. Ten plan obejmuje funkcje takie jak dedykowane zarządzanie kontem, niestandardowe ceny za GB i wsparcie 24/7.
Ponadto, jeśli chcesz ZAOSZCZĘDZIĆ więcej, możesz płacić co roku i zaoszczędź do 40%.
W jaki sposób przeglądarki ze skrobaniem przewyższają przeglądarki bezgłowe?
Scraping Browser, przeglądarka GUI (graficzny interfejs użytkownika), przewyższa przeglądarki bezgłowe na kilka sposobów, jeśli chodzi o skalowanie projektów zgarniania danych i omijanie blokad.
1. Pomijanie oprogramowania do wykrywania botów
Oprogramowanie do wykrywania botów staje się coraz bardziej wyrafinowane, co utrudnia programistom pobieranie danych ze stron internetowych.
Oprogramowanie do wykrywania botów jest w stanie z łatwością wykryć przeglądarki bezgłowe, które są powszechnie używane do przeszukiwania sieci.
Jednak Scraping Browser jest mniej prawdopodobny do wykrycia, ponieważ korzysta z interfejsu GUI, co sprawia, że wygląda bardziej jak prawdziwa przeglądarka użytkownika.
Oznacza to, że programiści mogą używać Scraping Browser do zbierania danych bez obawy o wykrycie i zablokowanie.
2. Wbudowane funkcje odblokowywania stron internetowych
Blokady witryn są automatycznie odblokowywane przez Scraping Browser. Funkcje te obejmują rozwiązywanie CAPTCHA, pobieranie odcisków palców przeglądarek, automatyczne ponawianie próby, wybieranie nagłówków i plików cookie oraz renderowanie JavaScript.
Oznacza to, że programiści nie muszą poświęcać czasu i zasobów na ręczne odblokowywanie stron internetowych lub znajdowanie obejść zablokowanych treści. Scraping Browser zajmuje się tym wszystkim automatycznie.

3. Łatwe do skalowania
Scraping Browser jest hostowany na Bright Data's, co oznacza, że programiści mogą łatwo skalować swoje projekty web scrapingu, otwierając tyle przeglądarek, ile potrzebują, bez konieczności inwestowania w kosztowną infrastrukturę wewnętrzną.
Ułatwia to zarządzanie dużymi projektami zbierania danych i zapewnia programistom szybki i wydajny dostęp do potrzebnych im danych.
4. Możliwość interakcji ze stronami internetowymi
Przeglądarka skrobająca to przeglądarka GUI, co oznacza, że programiści mogą jej używać do interakcji ze stronami internetowymi w sposób, który nie jest możliwy w przypadku przeglądarek bezobsługowych.
Na przykład programiści mogą najeżdżać kursorem na strony, klikać przyciski, przewijać i dodawać tekst. To sprawia, że przeglądarka Scraping Browser jest idealnym wyborem do projektów typu „web scraping”, które wymagają interakcji ze stroną internetową w celu pobrania danych.
5. Ulepszone możliwości debugowania
Scraping Browser zapewnia ulepszone możliwości debugowania w porównaniu do przeglądarek bezgłowych.
Deweloperzy mogą korzystać z interfejsu GUI, aby zobaczyć, co dzieje się na stronie internetowej w czasie rzeczywistym i mogą łatwo zidentyfikować wszelkie problemy lub błędy, które występują podczas procesu skrobania.
Ułatwia to rozwiązywanie problemów i zapewnia prawidłowe usuwanie danych.
Często zadawane pytania dotyczące Bright Data Skrobanie recenzji przeglądarki 2024
👉 Kiedy konieczne jest użycie automatycznej przeglądarki do scrapingu?
Zautomatyzowane przeglądarki są używane do zbierania danych, gdy wymagane jest renderowanie strony w języku JavaScript lub interakcje z witryną, takie jak najeżdżanie kursorem, zmiana stron, klikanie i robienie zrzutów ekranu. Są również przydatne w przypadku dużych projektów zbierania danych, których celem jest wiele stron.
👉 Czym jest przeglądarka Scraping?
Scraping Browser to zautomatyzowana przeglądarka kontrolowana przez interfejsy API wysokiego poziomu, takie jak Puppeteer i Playwright. Odblokowywanie witryny jest przez nią automatycznie obsługiwane, w tym rozwiązywanie CAPTCHA, pobieranie odcisków palców, wybór nagłówka, automatyczne ponowne próby i renderowanie JavaScript.
🤔 Czy przeglądarka Scraping Browser jest przeglądarką bezgłową czy zamyśloną?
Przeglądarka Scraping korzysta z graficznego interfejsu użytkownika i jest również nazywana przeglądarką headful. Jednak programiści współpracują ze Scraping Browser za pośrednictwem interfejsu API, takiego jak Puppeteer lub Playwright, dzięki czemu jest funkcjonalnie bezgłowy. Scraping Browser jest otwierany jako przeglądarka z graficznym interfejsem użytkownika Bright Datainfrastruktura.
👉 Jaka jest różnica między przeglądarką headless a headful, jeśli chodzi o scraping?
Przeglądarki bezgłowe odnoszą się do przeglądarek internetowych bez graficznego interfejsu użytkownika i mogą być używane do zbierania danych, gdy są używane z serwerem proxy. Są one jednak łatwo wykrywane przez oprogramowanie chroniące przed botami, co utrudnia zbieranie danych na dużą skalę. Przeglądarki GUI, takie jak Scraping Browser, używają graficznego interfejsu użytkownika i jest mniej prawdopodobne, że zostaną wykryte przez oprogramowanie wykrywające boty.
🤔 Co sprawia, że Scraping Browser jest lepszy od web scrapingu Chrome Headless lub Python Selenium?
Scraping Browser jest wyposażony w funkcję automatycznego odblokowywania, która automatycznie usuwa ograniczenia. Możliwe jest skalowanie projektów zbierania danych sieciowych bez wymagań infrastrukturalnych za pomocą przeglądarek Scraping Browser, które wykorzystują automatyczne odblokowywanie i działają na Bright Dataserwery użytkownika.
👉 Czy Scraping Browser jest kompatybilny ze scrapingiem Puppeteer?
Tak, Scraping Browser jest w pełni kompatybilny z Puppeteer.
🤔 Kiedy powinienem używać przeglądarki Scraping Browser zamiast innej Bright Data produkty zastępcze?
Scraping Browser to zautomatyzowana przeglądarka przeznaczona do zgarniania danych, obsługiwana przez technologię automatycznego odblokowywania Web Unlocker. Skrobanie przeglądarki jest konieczne, gdy programista musi wejść w interakcję ze stroną internetową, aby pobrać jej dane. Jest również idealny do każdego projektu zbierania danych, który wymaga przeglądarek, skalowania i automatycznego zarządzania wszystkimi działaniami odblokowującymi witrynę.
Szybkie linki:
Wnioski: Bright Data Skrobanie recenzji przeglądarki 2024
Podsumowując, zbieranie danych może być trudnym zadaniem, zwłaszcza w przypadku blokad witryn i innych skryptów wykrywających boty.
Połączenia Bright Data Scraping Browser to zautomatyzowana przeglądarka typu „wszystko w jednym”, która sprawia, że skrobanie danych jest łatwiejsze i bardziej wydajne.
Dzięki kompatybilności z Puppeteer, automatycznemu odblokowywaniu witryn, rozwiązywaniu CAPTCHA, odciskom palców, ponownym próbom i nie tylko, oferuje szeroki zakres funkcji i korzyści.
Jest to doskonałe narzędzie do skalowania, oszczędza zasoby i czas oraz jest idealne do obsługi złożonych operacji odblokowywania.