Alla ricerca di un dettagliato Bright Data Raschiare la revisione del browser, Non preoccuparti, ti ho coperto.
Internet è un enorme pool di dati che può essere incredibilmente prezioso per aziende, ricercatori e individui. Tuttavia, l'accesso a questi dati può essere un compito arduo, soprattutto quando si tratta di data scraping.
Lo scraping dei dati è il processo di estrazione automatica dei dati dai siti Web ed è spesso utilizzato per scopi di ricerca, marketing e altri scopi.
Lo scraping dei dati può essere eseguito manualmente, ma si tratta di un processo che richiede tempo e richiede molta competenza tecnica.
Fortunatamente, sono disponibili strumenti e servizi software in grado di automatizzare il processo di scraping dei dati e semplificare l'accesso ai dati necessari.
Ma può anche essere impegnativo, soprattutto quando si ha a che fare con blocchi del sito, CAPTCHA e altri script di rilevamento dei bot. Il costo totale medio di una violazione dei dati è stato di 3.62 milioni di dollari nel 2017, con una diminuzione del 10% rispetto allo scorso anno.
Ecco dove il Bright Data Entra Scraping Browser. Quindi, discutiamo in dettaglio su come il file Bright Data Scraping Browser ti aiuta nello scraping dei dati nel nostro dettagliato Bright Data Recensione di Scraping Browser.

Cosa è Bright Data Raschiare il browser?
I Bright Data Browser raschiante è un browser automatizzato all-in-one progettato specificamente per scopi di scraping dei dati.
È alimentato da una pluripremiata rete proxy che offre oltre 72 milioni di IP e la possibilità di scegliere come target qualsiasi paese, città, operatore e ASN.
Questo premio servizio proxy è la scelta migliore per gli sviluppatori che hanno bisogno di raccogliere dati su larga scala. Inoltre, è compatibile con Puppeteer, il che significa che è più potente dei browser automatizzati e senza testa.
I Bright Data Scraping Browser è progettato per rendere lo scraping dei dati veloce, facile e sicuro. Utilizza tecnologie avanzate come il captcha guidato dall'intelligenza artificiale e il rilevamento dei bot che garantisce un'estrazione dei dati fluida.
Grazie alla Bright Data Scraping Browser, gli utenti possono estrarre dati in modo rapido e sicuro da qualsiasi sito Web senza problemi.
Caratteristiche di Bright Data Browser raschiante
Bright DataIl browser scraping di offre una serie di funzionalità progettate per aiutarti Scraping Web su larga scala.
1. Gestione automatica delle operazioni di sblocco del sito web
Il programma ha una caratteristica chiave della gestione automatica delle operazioni di sblocco del sito web. Ciò include la risoluzione di CAPTCHA, browser di impronte digitali e una varietà di altre attività.
Ciò può far risparmiare tempo e risorse agli sviluppatori che hanno bisogno di prelevare grandi quantità di dati dai siti web.
2. Supera in astuzia il software di rilevamento dei bot
Un'altra importante caratteristica di Bright DataIl browser scraping di è la sua capacità di superare in astuzia il software di rilevamento dei bot.
Oltre a bypassare sistemi di rilevamento dei bot utilizzando la tecnologia AI, gli scraper possono anche produrre migliori tassi di sblocco quando si utilizzano proxy invece della tecnologia AI.

3. Altamente scalabile
Bright DataIl browser di scraping di è anche altamente scalabile, consentendo agli sviluppatori di far crescere i loro progetti di scraping con tutti i browser di cui hanno bisogno.
I browser sono ospitati su Bright Data, progettata per gestire grandi quantità di traffico e richieste.
4. Compatibile sia con Puppeteer (Python) che con Playwright (Node.js)
Infine, Bright DataIl browser scraping di è compatibile sia con Puppeteer (Python) che con Playwright (Node.js), che consente agli sviluppatori di interagire con le sessioni del browser ed eseguire interazioni con il sito Web per recuperare i dati.
Questo può essere utile per lo scraping di progetti che richiedono di fare clic su pulsanti, scorrere o aggiungere testo alle pagine web.
Prezzi
Il prezzo del Bright Data Scraping Browser è progettato per essere flessibile e accessibile alle aziende di tutte le dimensioni, dalle piccole startup alle grandi imprese.
L'azienda offre quattro livelli di prezzo, tra cui Pay As You Go, Growth, Business ed Enterprise, per soddisfare le esigenze dei diversi utenti.
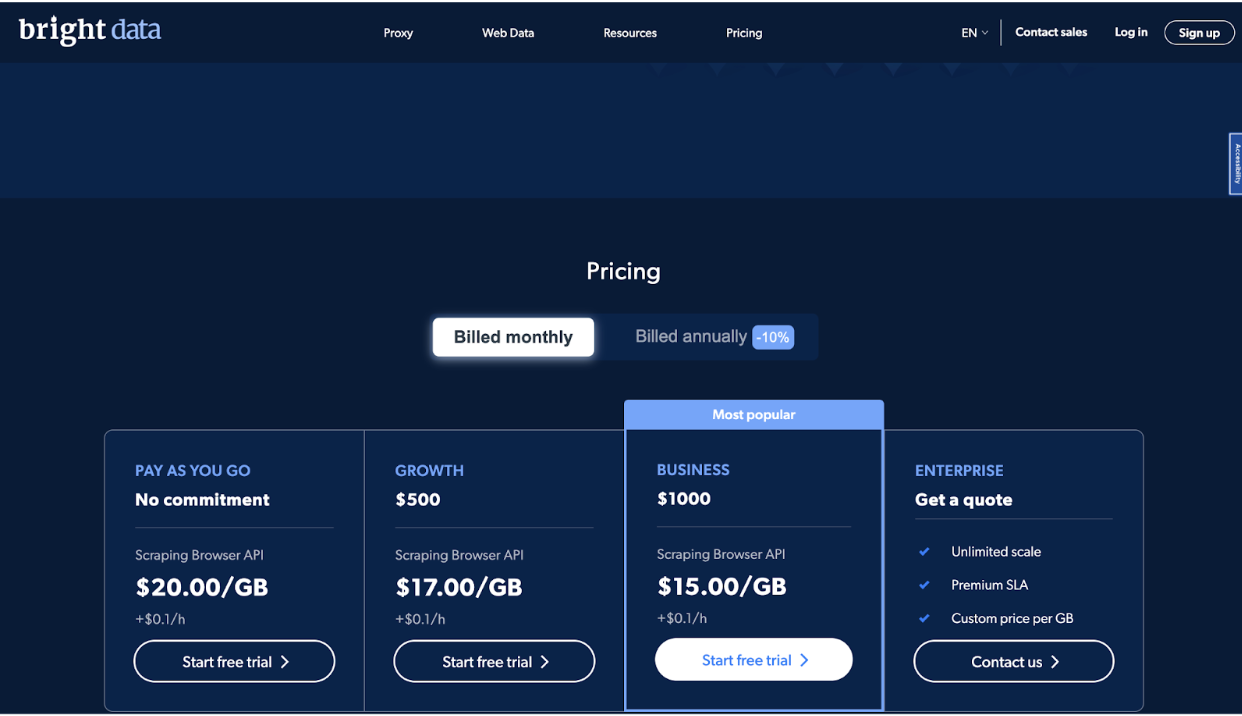
Il piano Pay As You Go è progettato per gli utenti che hanno bisogno di raccogliere dati occasionalmente o in piccoli volumi. È un piano senza impegno che ti consente di pagare solo ciò che usi. Il prezzo per questo piano è $ 20.00 per GB, più $ 0.1 all'ora.
Il piano di crescita è ideale per le aziende che hanno bisogno di acquisire dati più frequentemente o in volumi maggiori. Include un sconto di 10% sul Piano a consumo e costi $ 500 al mese. Il prezzo per questo piano è $ 17.00 per GB, più $ 0.1 all'ora.
Il piano aziendale è il piano più popolare ed è progettato per le aziende che devono ridimensionare le proprie operazioni di scraping dei dati.
Include uno sconto del 25% sul piano Pay As You Go e costa $ 1000 al mese. Il prezzo per questo piano è $ 15.00 per GB, più $ 0.1 all'ora.
Infine, il piano Enterprise è progettato per le aziende che necessitano di scalabilità illimitata e a accordo sul livello di servizio premium (SLA).
Il prezzo per questo piano è personalizzato e si basa sulle tue esigenze e requisiti specifici. Questo piano include funzionalità come gestione dell'account dedicata, prezzi personalizzati per GB e supporto 24 ore su 7, XNUMX giorni su XNUMX.
Inoltre, se desideri RISPARMIARE di più, puoi pagare annualmente e salva fino a 40%.
In che modo i browser di scraping superano i browser senza testa?
Scraping Browser, un browser GUI (Graphical User Interface), supera i browser senza testa in diversi modi quando si tratta di ridimensionare i progetti di scraping dei dati e aggirare i blocchi.
1. Bypassare il software di rilevamento dei bot
Il software di rilevamento dei bot sta diventando sempre più sofisticato, rendendo difficile per gli sviluppatori estrarre dati dai siti web.
Il software di rilevamento dei bot è facilmente in grado di rilevare i browser senza testa, che sono comunemente usati per raschiare il web.
Tuttavia, è meno probabile che Scraping Browser venga rilevato perché utilizza un'interfaccia GUI, che lo fa apparire più simile a un vero browser utente.
Ciò significa che gli sviluppatori possono utilizzare Scraping Browser per eseguire lo scraping dei dati senza preoccuparsi di essere rilevati e bloccati.
2. Funzioni di sblocco del sito Web integrate
I blocchi del sito Web vengono sbloccati automaticamente da Scraping Browser. Queste funzioni includono la risoluzione di CAPTCHA, il fingerprinting dei browser, i tentativi automatici, la selezione di intestazioni e cookie e il rendering di JavaScript.
Ciò significa che gli sviluppatori non devono dedicare tempo e risorse allo sblocco manuale dei siti Web o alla ricerca di soluzioni alternative per i contenuti bloccati. Scraping Browser si occupa di tutto automaticamente.

3. Facile da scalare
Scraping Browser è ospitato su Bright Data, il che significa che gli sviluppatori possono facilmente ridimensionare i loro progetti di web scraping aprendo tutti i browser di scraping di cui hanno bisogno senza dover investire in costose infrastrutture interne.
Ciò semplifica la gestione di grandi progetti di data scraping e garantisce che gli sviluppatori possano accedere ai dati di cui hanno bisogno in modo rapido ed efficiente.
4. Capacità di interagire con i siti web
Un browser scraping è un browser GUI, il che significa che gli sviluppatori possono utilizzarlo per interagire con i siti Web in modi che non sono possibili con i browser headless.
Ad esempio, gli sviluppatori possono passare con il mouse sulle pagine, fare clic sui pulsanti, scorrere e aggiungere testo. Ciò rende Scraping Browser la scelta ideale per i progetti di web scraping che richiedono interazioni con il sito Web per recuperare i dati.
5. Funzionalità di debug migliorate
Scraping Browser offre funzionalità di debug avanzate rispetto ai browser headless.
Gli sviluppatori possono utilizzare l'interfaccia GUI per vedere cosa sta succedendo sul sito Web in tempo reale e possono facilmente identificare eventuali problemi o errori che si verificano durante il processo di scraping.
Ciò semplifica la risoluzione dei problemi e garantisce che i dati vengano raschiati correttamente.
Domande frequenti su Bright Data Recensione del browser scraping 2024
👉 Quando è necessario utilizzare un browser automatizzato per lo scraping?
I browser automatizzati vengono utilizzati per lo scraping dei dati quando è richiesto il rendering JavaScript di una pagina o interazioni con un sito Web, come il passaggio del mouse, la modifica di pagine, il clic e l'acquisizione di schermate. Sono anche utili per progetti di scraping di dati su larga scala destinati a più pagine.
👉 Cos'è Scraping Browser?
Scraping Browser è un browser automatizzato controllato da API di alto livello come Puppeteer e Playwright. Lo sblocco del sito Web viene gestito automaticamente sotto il cofano da esso, inclusa la risoluzione CAPTCHA, l'impronta digitale, la selezione dell'intestazione, i tentativi automatici e il rendering JavaScript.
🤔 Scraping Browser è un browser senza testa o con testa?
Lo Scraping Browser utilizza un'interfaccia utente grafica ed è anche chiamato browser headful. Tuttavia, gli sviluppatori interagiscono con Scraping Browser tramite un'API come Puppeteer o Playwright, rendendolo funzionalmente senza testa. Scraping Browser viene aperto come browser GUI attivo Bright Data's infrastruttura.
👉 Qual è la differenza tra un browser senza testa e uno con testa quando si tratta di scraping?
I browser senza testa si riferiscono a browser Web senza un'interfaccia utente grafica e possono essere utilizzati per raccogliere dati se utilizzati con un proxy. Tuttavia, vengono facilmente rilevati dal software di protezione dai bot, rendendo difficile lo scraping di dati su larga scala. I browser GUI, come Scraping Browser, utilizzano un'interfaccia utente grafica e hanno meno probabilità di essere rilevati dal software di rilevamento dei bot.
🤔 Cosa rende Scraping Browser superiore a Chrome Headless o Python Selenium web scraping?
Scraping Browser è dotato di una funzione di sblocco automatico che rimuove automaticamente le restrizioni. È possibile ridimensionare i progetti di scraping dei dati Web senza requisiti infrastrutturali utilizzando i browser di scraping, che utilizzano lo sblocco automatico e funzionano su Bright Datai server.
👉 Scraping Browser è compatibile con lo scraping di Puppeteer?
Sì, Scraping Browser è completamente compatibile con Puppeteer.
🤔 Quando dovrei usare Scraping Browser invece di altri Bright Data prodotti delegati?
Scraping Browser è un browser automatizzato dedicato allo scraping dei dati, basato sulla tecnologia di sblocco automatico di Web Unlocker. Lo scraping di un browser è necessario quando uno sviluppatore deve interagire con un sito Web per recuperarne i dati. È anche ideale per qualsiasi progetto di data scraping che richieda browser, ridimensionamento e gestione automatizzata di tutte le azioni di sblocco del sito web.
Link veloci:
Conclusione: Bright Data Recensione del browser scraping 2024
In conclusione, lo scraping dei dati può essere un compito impegnativo, soprattutto quando si ha a che fare con blocchi di siti Web e altri script di rilevamento dei bot.
I Bright Data Scraping Browser è un browser automatizzato all-in-one che rende lo scraping dei dati più semplice ed efficiente.
Con la compatibilità di Puppeteer, lo sblocco automatico dei siti, la risoluzione di CAPTCHA, le impronte digitali, i tentativi e altro ancora, offre un'ampia gamma di funzionalità e vantaggi.
È uno strumento eccellente per il ridimensionamento, consente di risparmiare risorse e tempo ed è ideale per gestire operazioni di sblocco complesse.