Buscando un detallado Bright Data Revisión del navegador de raspado, No te preocupes, te tengo cubierto.
Internet es un enorme conjunto de datos que puede ser increíblemente valioso para empresas, investigadores e individuos. Sin embargo, acceder a estos datos puede ser una tarea desalentadora, especialmente cuando se trata de raspado de datos.
El raspado de datos es el proceso de extracción automática de datos de sitios web y, a menudo, se usa para investigación, marketing y otros fines.
El raspado de datos se puede realizar manualmente, pero este es un proceso lento y requiere mucha experiencia técnica.
Afortunadamente, existen herramientas y servicios de software disponibles que pueden automatizar el proceso de extracción de datos y facilitar el acceso a los datos que necesita.
Pero también puede ser un desafío, especialmente cuando se trata de bloqueos de sitios, CAPTCHA y otros scripts de detección de bots. El coste total medio de una filtración de datos es de 3.62 millones de dólares en 2017, una disminución del 10 % con respecto al año pasado.
Ahí es donde el Bright Data Scraping Browser entra. Entonces, analicemos en detalle cómo el Bright Data Scraping Browser lo ayuda a raspar datos en nuestro detallado Bright Data Revisión del navegador de raspado.

Que es Bright Data Navegador de raspado?
El Bright Data Navegador de raspado es un navegador automatizado todo en uno diseñado específicamente para fines de extracción de datos.
Está alimentado por una red proxy galardonada que ofrece más de 72 millones de IP y la capacidad de dirigirse a cualquier país, ciudad, operador y ASN.
Esta prima servicio de proxy es la mejor opción para los desarrolladores que necesitan raspar datos a escala. Además, es compatible con Puppeteer, lo que significa que es más potente que los navegadores automatizados y sin cabeza.
El Bright Data Scraping Browser está diseñado para hacer que el raspado de datos sea rápido, fácil y seguro. Utiliza tecnologías avanzadas como captcha impulsado por IA y detección de bots que garantiza una extracción de datos sin problemas.
Con la Bright Data Scraping Browser, los usuarios pueden extraer datos de forma rápida y segura de cualquier sitio web sin problemas.
Caracteristicas de Bright Data Navegador de raspado
Bright DataEl navegador de raspado ofrece una serie de características diseñadas para ayudar con Raspado web a escala.
1. Gestión automática de operaciones de desbloqueo de sitios web
El programa tiene una característica clave de gestión automática de operaciones de desbloqueo de sitios web. Esto incluye resolver CAPTCHA, navegadores de huellas dactilares y una variedad de otras tareas.
Esto puede ahorrar tiempo y recursos a los desarrolladores que necesitan extraer grandes cantidades de datos de los sitios web.
2. Supere al software de detección de bots
Otra característica importante de Bright DataEl navegador de scraping es su capacidad para ser más astuto que el software de detección de bots.
Además de pasar por alto sistemas de detección de bots Al usar tecnología de inteligencia artificial, los raspadores también pueden producir mejores tasas de desbloqueo cuando se usan proxies en lugar de tecnología de inteligencia artificial.

3. Altamente escalable
Bright DataEl navegador de scraping de también es altamente escalable, lo que permite a los desarrolladores hacer crecer sus proyectos de scraping con tantos navegadores como necesiten.
Los navegadores están alojados en Bright DataLa infraestructura de , que está diseñada para manejar grandes cantidades de tráfico y solicitudes.
4. Compatible con Titiritero (Python) y Dramaturgo (Node.js)
Finalmente, Bright DataEl navegador de raspado es compatible tanto con Puppeteer (Python) como con Playwright (Node.js), lo que permite a los desarrolladores interactuar con las sesiones del navegador y realizar interacciones en el sitio web para recuperar datos.
Esto puede ser útil para raspar proyectos que requieren hacer clic en botones, desplazarse o agregar texto a páginas web.
Precios
El precio de la Bright Data Scraping Browser está diseñado para ser flexible y accesible para empresas de todos los tamaños, desde pequeñas empresas emergentes hasta grandes empresas.
La empresa ofrece cuatro niveles de precios, incluidos Pay As You Go, Growth, Business y Enterprise, para satisfacer las necesidades de los diferentes usuarios.
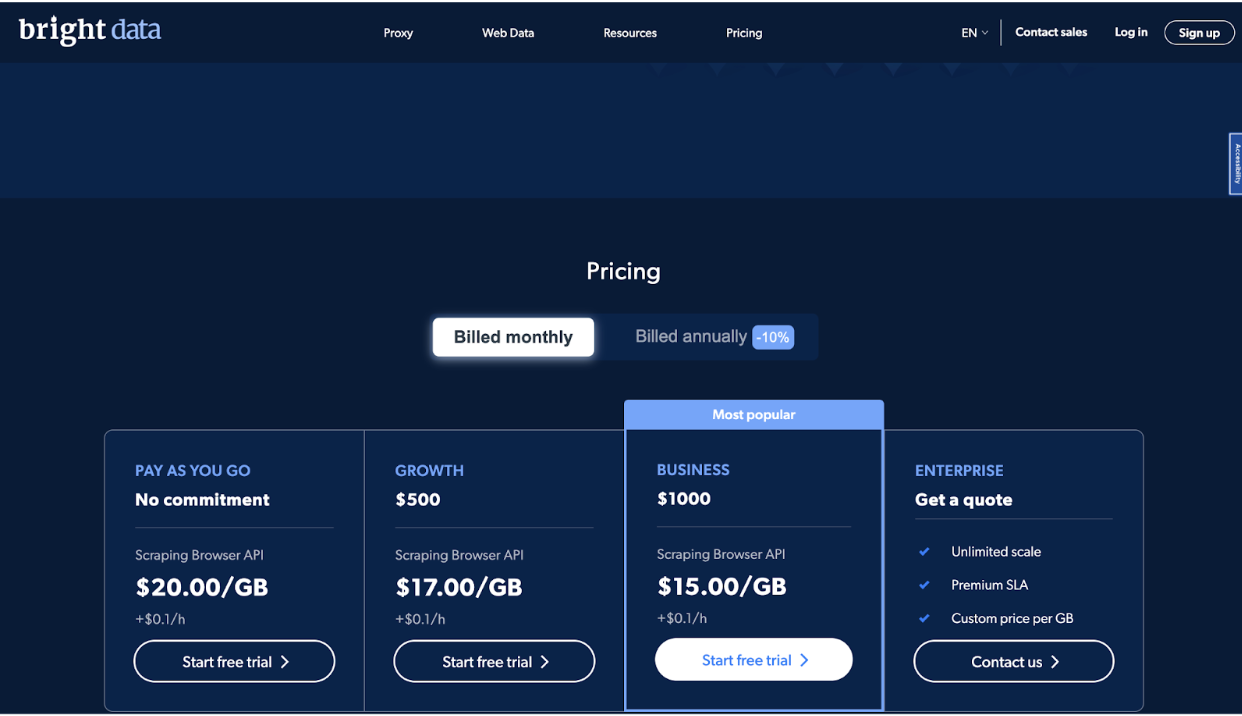
El plan Pay As You Go está diseñado para usuarios que necesitan raspar datos ocasionalmente o en pequeños volúmenes. Es un plan sin compromiso que te permite pagar solo por lo que usas. El precio de este plan es $20.00 por GB, más $0.1 por hora.
El plan Growth es ideal para empresas que necesitan recopilar datos con mayor frecuencia o en volúmenes más grandes. Incluye un descuento de 10% en Plan de pago por uso y costos $ 500 por mes. El precio de este plan es $17.00 por GB, más $0.1 por hora.
El plan Business es el plan más popular y está diseñado para empresas que necesitan escalar sus operaciones de extracción de datos.
Incluye un descuento del 25% en el plan Pay As You Go y cuesta $1000 por mes. El precio de este plan es $15.00 por GB, más $0.1 por hora.
Finalmente, el plan Enterprise está diseñado para empresas que necesitan una escala ilimitada y una acuerdo de nivel de servicio premium (SLA).
El precio de este plan es personalizado y se basa en sus necesidades y requisitos específicos. Este plan incluye funciones como administración de cuenta dedicada, precios personalizados por GB y soporte 24/7.
Además, si desea AHORRAR más, puede pagar anualmente y ahorra hasta un 40%.
¿Cómo los navegadores de raspado superan a los navegadores sin cabeza?
Scraping Browser, un navegador GUI (interfaz gráfica de usuario), supera a los navegadores sin cabeza de varias maneras cuando se trata de escalar proyectos de extracción de datos y omitir bloques.
1. Omitir el software de detección de bots
El software de detección de bots se está volviendo cada vez más sofisticado, lo que dificulta que los desarrolladores extraigan datos de los sitios web.
El software de detección de bots puede detectar fácilmente los navegadores sin cabeza, que se usan comúnmente para raspar la web.
Sin embargo, es menos probable que se detecte Scraping Browser porque utiliza una interfaz GUI, lo que hace que se parezca más a un navegador de usuario real.
Esto significa que los desarrolladores pueden usar Scraping Browser para raspar datos sin preocuparse por ser detectados y bloqueados.
2. Funciones integradas de desbloqueo de sitios web
Los bloques de sitios web se desbloquean automáticamente mediante Scraping Browser. Estas funciones incluyen la resolución de CAPTCHA, la toma de huellas dactilares de los navegadores, el reintento automático, la selección de encabezados y cookies, y la representación de JavaScript.
Esto significa que los desarrolladores no tienen que gastar tiempo y recursos desbloqueando sitios web manualmente o buscando soluciones para el contenido bloqueado. Scraping Browser se encarga de todo automáticamente.

3. Fácil de escalar
Scraping Browser está alojado en Bright Data, lo que significa que los desarrolladores pueden escalar fácilmente sus proyectos de web scraping abriendo tantos Scraping Browsers como necesiten sin tener que invertir en una costosa infraestructura interna.
Esto facilita la gestión de grandes proyectos de extracción de datos y garantiza que los desarrolladores puedan acceder a los datos que necesitan de forma rápida y eficiente.
4. Capacidad para interactuar con sitios web
Un navegador de raspado es un navegador GUI, lo que significa que los desarrolladores pueden usarlo para interactuar con sitios web de formas que no son posibles con los navegadores sin cabeza.
Por ejemplo, los desarrolladores pueden pasar el cursor sobre las páginas, hacer clic en los botones, desplazarse y agregar texto. Esto hace que Scraping Browser sea una opción ideal para proyectos de web scraping que requieren interacciones con sitios web para recuperar datos.
5. Capacidades de depuración mejoradas
Scraping Browser proporciona capacidades de depuración mejoradas en comparación con los navegadores sin interfaz.
Los desarrolladores pueden usar la interfaz GUI para ver lo que sucede en el sitio web en tiempo real y pueden identificar fácilmente cualquier problema o error que ocurra durante el proceso de raspado.
Esto facilita la resolución de problemas y garantiza que los datos se extraigan correctamente.
Preguntas frecuentes sobre Bright Data Revisión del navegador de raspado 2024
👉 ¿Cuándo es necesario usar un navegador automatizado para raspar?
Los navegadores automatizados se utilizan para el raspado de datos cuando se requiere la representación de JavaScript de una página o las interacciones con un sitio web, como pasar el mouse, cambiar de página, hacer clic y tomar capturas de pantalla. También son útiles para proyectos de extracción de datos a gran escala que tienen como objetivo varias páginas.
👉 ¿Qué es el navegador de raspado?
Scraping Browser es un navegador automatizado controlado por API de alto nivel como Puppeteer y Playwright. El desbloqueo de sitios web se maneja automáticamente bajo el capó, incluida la resolución de CAPTCHA, la toma de huellas digitales, la selección de encabezados, los reintentos automáticos y la representación de JavaScript.
🤔 ¿Scraping Browser es un navegador sin cabeza o con cabeza?
Scraping Browser utiliza una interfaz gráfica de usuario y también se denomina navegador headful. Sin embargo, los desarrolladores interactúan con Scraping Browser a través de una API como Puppeteer o Playwright, lo que lo hace funcionalmente sin cabeza. Scraping Browser se abre como un navegador GUI en Bright Datainfraestructura de .
👉 ¿Cuál es la diferencia entre un navegador sin cabeza y uno con cabeza cuando se trata de raspar?
Los navegadores sin cabeza se refieren a navegadores web sin una interfaz gráfica de usuario, y se pueden usar para extraer datos cuando se usan con un proxy. Sin embargo, el software de protección contra bots los detecta fácilmente, lo que dificulta el raspado de datos a gran escala. Los navegadores GUI, como Scraping Browser, utilizan una interfaz gráfica de usuario y es menos probable que los detecte el software de detección de bots.
🤔 ¿Qué hace que Scraping Browser sea superior a Chrome Headless o Python Selenium web scraping?
Scraping Browser viene con una función de desbloqueo automático que elimina automáticamente las restricciones. Es posible escalar proyectos de raspado de datos web sin requisitos de infraestructura mediante el uso de navegadores de raspado, que emplean el desbloqueo automático y se ejecutan en Bright Dataservidores de .
👉 ¿Es Scraping Browser compatible con Puppeteer scraping?
Sí, Scraping Browser es totalmente compatible con Puppeteer.
🤔 ¿Cuándo debo usar Scraping Browser en lugar de otros? Bright Data productos proxy?
Scraping Browser es un navegador automatizado dedicado a raspar datos, impulsado por la tecnología de desbloqueo automatizado de Web Unlocker. Es necesario raspar un navegador cuando un desarrollador necesita interactuar con un sitio web para recuperar sus datos. También es ideal para cualquier proyecto de extracción de datos que requiera navegadores, escalado y gestión automatizada de todas las acciones de desbloqueo de sitios web.
Quick Links:
- Revisión De Spyic
- Estadísticas, hechos y cifras del navegador
- Revisión de Kameleo
- Revisión de Flixtor
Conclusión: Bright Data Revisión del navegador de raspado 2024
En conclusión, el raspado de datos puede ser una tarea desafiante, especialmente cuando se trata de bloqueos de sitios web y otros scripts de detección de bots.
El Bright Data Scraping Browser es un navegador automatizado todo en uno que hace que el raspado de datos sea más fácil y eficiente.
Con compatibilidad con Puppeteer, desbloqueo automático de sitios, resolución de CAPTCHA, huellas dactilares, reintentos y más, ofrece una amplia gama de características y beneficios.
Es una excelente herramienta para escalar, ahorra recursos y tiempo, y es ideal para manejar operaciones complejas de desbloqueo.