Auf der Suche nach einem ausführlichen Bright Data Überprüfung des Scraping-Browsers, Keine Sorge, ich habe dich abgedeckt.
Das Internet ist ein riesiger Datenpool, der für Unternehmen, Forscher und Einzelpersonen unglaublich wertvoll sein kann. Der Zugriff auf diese Daten kann jedoch eine entmutigende Aufgabe sein, insbesondere wenn es um Data Scraping geht.
Data Scraping ist der Prozess des automatischen Extrahierens von Daten von Websites und wird häufig für Forschungs-, Marketing- und andere Zwecke verwendet.
Data Scraping kann manuell durchgeführt werden, dies ist jedoch ein zeitaufwändiger Prozess und erfordert viel technisches Know-how.
Glücklicherweise gibt es Software-Tools und -Dienste, die den Daten-Scraping-Prozess automatisieren und den Zugriff auf die benötigten Daten erleichtern können.
Aber es kann auch eine Herausforderung sein, besonders wenn es um Seitenblöcke, CAPTCHA und andere Bot-Erkennungsskripte geht. Die durchschnittlichen Gesamtkosten einer Datenschutzverletzung belaufen sich im Jahr 3.62 auf 2017 Millionen US-Dollar, was einem Rückgang von 10 Prozent gegenüber dem Vorjahr entspricht.
Das ist, wo die Bright Data Scraping Browser kommt ins Spiel. Lassen Sie uns also im Detail darüber diskutieren, wie der Bright Data Scraping Browser hilft Ihnen beim Daten-Scraping in unserem Detail Bright Data Überprüfung des Scraping-Browsers.

Was ist Bright Data Scraping-Browser?
Das Bright Data Scraping-Browser ist ein automatisierter All-in-One-Browser, der speziell für Data-Scraping-Zwecke entwickelt wurde.
Es wird von einem preisgekrönten Proxy-Netzwerk betrieben, das über bietet 72 Millionen IPs und die Möglichkeit, jedes Land, jede Stadt, jeden Spediteur und jede ASN anzusprechen.
Diese Prämie Proxy-Service ist die erste Wahl für Entwickler, die Daten in großem Umfang kratzen müssen. Darüber hinaus ist es Puppeteer-kompatibel, was bedeutet, dass es leistungsfähiger ist als automatisierte und kopflose Browser.
Das Bright Data Scraping Browser wurde entwickelt, um das Scraping von Daten schnell, einfach und sicher zu machen. Es verwendet fortschrittliche Technologien wie KI-gesteuertes Captcha und Bot-Erkennung, die eine reibungslose Datenextraktion gewährleisten.
Mit der Bright Data Scraping Browser können Benutzer schnell und sicher Daten von jeder Website ohne Probleme extrahieren.
Merkmale Bright Data Scraping-Browser
Bright DataDer Scraping-Browser von bietet eine Reihe hilfreicher Funktionen Web Scraping auf einer Skala.
1. Automatische Verwaltung von Website-Entsperrvorgängen
Das Programm verfügt über eine Schlüsselfunktion zur automatischen Verwaltung von Website-Entsperrvorgängen. Dazu gehören das Lösen von CAPTCHAs, Fingerabdrücken von Browsern und eine Vielzahl anderer Aufgaben.
Dies kann Zeit und Ressourcen für Entwickler sparen, die große Datenmengen von Websites entfernen müssen.
2. Software zur Bot-Erkennung überlisten
Ein weiteres wichtiges Merkmal von Bright DataDer Scraping-Browser von ist seine Fähigkeit, Bot-Erkennungssoftware zu überlisten.
Neben Umgehung Bot-Erkennungssysteme Mithilfe von KI-Technologie können Scraper auch bessere Entsperrraten erzielen, wenn Proxys anstelle von KI-Technologie verwendet werden.

3. Hochgradig skalierbar
Bright DataDer Scraping-Browser von ist außerdem hochgradig skalierbar, sodass Entwickler ihre Scraping-Projekte mit so vielen Browsern erweitern können, wie sie benötigen.
Die Browser werden auf gehostet Bright DataDie Infrastruktur von , die darauf ausgelegt ist, große Mengen an Datenverkehr und Anfragen zu verarbeiten.
4. Kompatibel mit Puppeteer (Python) und Playwright (Node.js)
Schließlich Bright DataDer Scraping-Browser von ist sowohl mit Puppeteer (Python) als auch mit Playwright (Node.js) kompatibel, wodurch Entwickler mit Browsersitzungen interagieren und Website-Interaktionen durchführen können, um Daten abzurufen.
Dies kann beim Scraping von Projekten nützlich sein, bei denen auf Schaltflächen geklickt, gescrollt oder Text zu Webseiten hinzugefügt werden muss.
AnzeigenPreise
Die Preise der Bright Data Der Scraping Browser ist so konzipiert, dass er flexibel und für Unternehmen jeder Größe zugänglich ist, von kleinen Startups bis hin zu großen Unternehmen.
Das Unternehmen bietet vier Preisstufen an, darunter Pay As You Go, Growth, Business und Enterprise, um den Anforderungen verschiedener Benutzer gerecht zu werden.
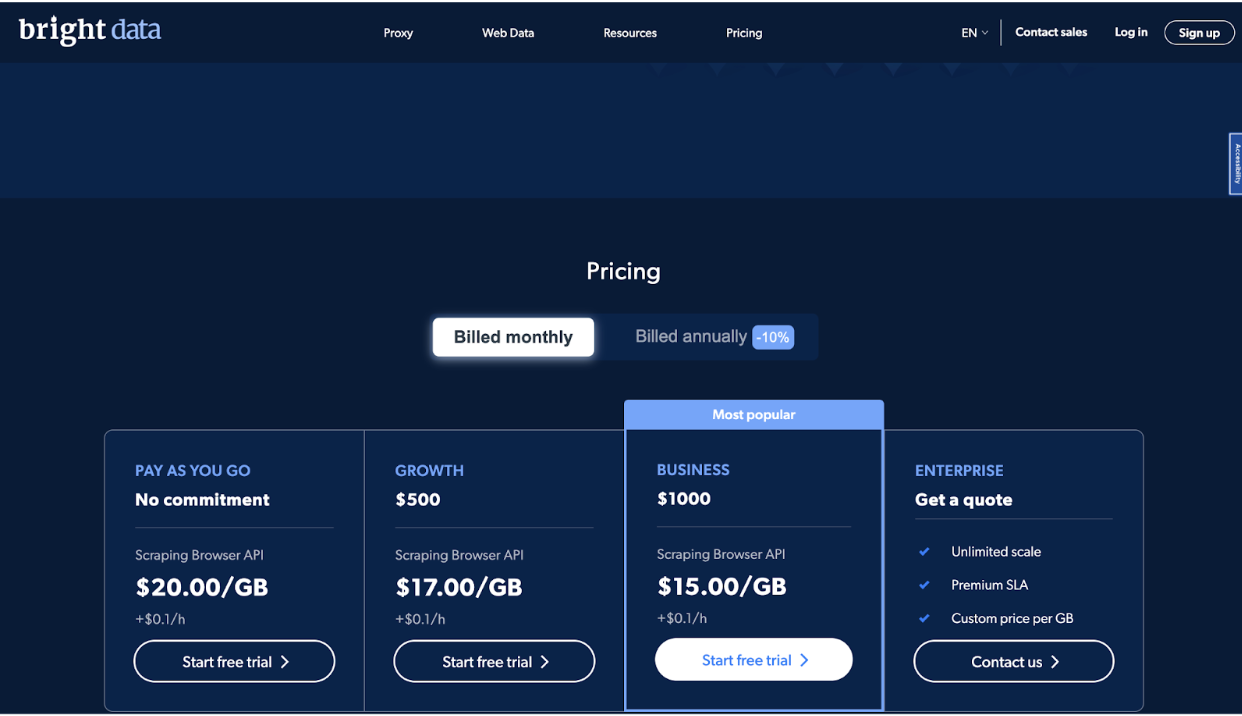
Der Pay-As-You-Go-Plan ist für Benutzer konzipiert, die gelegentlich oder in kleinen Mengen Daten scrapen müssen. Es handelt sich um einen unverbindlichen Plan, bei dem Sie nur für das bezahlen, was Sie nutzen. Der Preis für diesen Plan beträgt 20.00 $ pro GB plus 0.1 $ pro Stunde.
Der Wachstumsplan ist ideal für Unternehmen, die Daten häufiger oder in größeren Mengen auslesen müssen. Es beinhaltet ein Rabatt von 10% auf die Pay As You Go-Plan und Kosten $ Pro Monat 500. Der Preis für diesen Plan beträgt 17.00 $ pro GB plus 0.1 $ pro Stunde.
Der Business-Plan ist der beliebteste Plan und wurde für Unternehmen entwickelt, die ihre Data-Scraping-Vorgänge skalieren müssen.
Es beinhaltet einen Rabatt von 25 % auf den Pay-As-You-Go-Plan und kostet 1000 $ pro Monat. Der Preis für diesen Plan beträgt 15.00 $ pro GB plus 0.1 $ pro Stunde.
Schließlich ist der Enterprise-Plan für Unternehmen konzipiert, die eine unbegrenzte Skalierung benötigen und a Premium-Service-Level-Vereinbarung (SLA).
Die Preise für diesen Plan sind kundenspezifisch und basieren auf Ihren spezifischen Bedürfnissen und Anforderungen. Dieser Plan enthält Funktionen wie dedizierte Kontoverwaltung, benutzerdefinierte Preise pro GB und Support rund um die Uhr.
Wenn Sie mehr SPAREN möchten, können Sie auch jährlich zahlen und Sparen bis zu 40%.
Wie Scraping-Browser Headless-Browser übertreffen?
Scraping Browser, ein GUI-Browser (Graphical User Interface), übertrifft Headless-Browser in mehrfacher Hinsicht, wenn es darum geht, Daten-Scraping-Projekte zu skalieren und Blöcke zu umgehen.
1. Umgehen von Bot-Erkennungssoftware
Bot-Erkennungssoftware wird immer ausgefeilter, was es Entwicklern erschwert, Daten von Websites zu kratzen.
Bot-Erkennungssoftware ist leicht in der Lage, Headless-Browser zu erkennen, die häufig zum Scrapen des Webs verwendet werden.
Es ist jedoch weniger wahrscheinlich, dass der Scraping Browser erkannt wird, da er eine GUI-Oberfläche verwendet, die ihn eher wie einen echten Benutzerbrowser erscheinen lässt.
Dies bedeutet, dass Entwickler den Scraping Browser verwenden können, um Daten zu scrapen, ohne sich Sorgen machen zu müssen, dass sie entdeckt und blockiert werden.
2. Integrierte Funktionen zum Entsperren von Websites
Website-Blöcke werden vom Scraping Browser automatisch entsperrt. Zu diesen Funktionen gehören das Lösen von CAPTCHAs, das Fingerprinting von Browsern, das automatische Wiederholen von Versuchen, das Auswählen von Headern und Cookies sowie das Rendern von JavaScript.
Dies bedeutet, dass Entwickler keine Zeit und Ressourcen aufwenden müssen, um Websites manuell zu entsperren oder Problemumgehungen für blockierte Inhalte zu finden. Scraping Browser erledigt das alles automatisch.

3. Einfach zu skalieren
Scraping Browser wird gehostet auf Bright Data's-Server, was bedeutet, dass Entwickler ihre Web-Scraping-Projekte einfach skalieren können, indem sie so viele Scraping-Browser öffnen, wie sie benötigen, ohne in eine teure interne Infrastruktur investieren zu müssen.
Dies erleichtert die Verwaltung großer Data-Scraping-Projekte und stellt sicher, dass Entwickler schnell und effizient auf die benötigten Daten zugreifen können.
4. Fähigkeit zur Interaktion mit Websites
Ein Scraping-Browser ist ein GUI-Browser, was bedeutet, dass Entwickler ihn verwenden können, um mit Websites auf eine Weise zu interagieren, die mit Headless-Browsern nicht möglich ist.
Beispielsweise können Entwickler mit der Maus über Seiten fahren, auf Schaltflächen klicken, scrollen und Text hinzufügen. Dies macht den Scraping-Browser zur idealen Wahl für Web-Scraping-Projekte, die Website-Interaktionen zum Abrufen von Daten erfordern.
5. Verbesserte Debugging-Fähigkeiten
Scraping Browser bietet verbesserte Debugging-Funktionen im Vergleich zu Headless-Browsern.
Entwickler können die GUI-Oberfläche verwenden, um in Echtzeit zu sehen, was auf der Website passiert, und können Probleme oder Fehler, die während des Scraping-Prozesses auftreten, leicht identifizieren.
Dies erleichtert die Fehlerbehebung und stellt sicher, dass die Daten korrekt geschabt werden.
FAQs Ein Bright Data Bewertung des Scraping-Browsers 2024
👉 Wann ist es notwendig, einen automatisierten Browser zum Scrapen zu verwenden?
Automatisierte Browser werden zum Data Scraping verwendet, wenn eine JavaScript-Wiedergabe einer Seite oder Interaktionen mit einer Website erforderlich sind, z. B. Bewegen der Maus, Wechseln von Seiten, Klicken und Erstellen von Screenshots. Sie sind auch nützlich für groß angelegte Data-Scraping-Projekte, die auf mehrere Seiten abzielen.
👉 Was ist ein Scraping-Browser?
Scraping Browser ist ein automatisierter Browser, der von High-Level-APIs wie Puppeteer und Playwright gesteuert wird. Das Entsperren von Websites wird automatisch unter der Haube durchgeführt, einschließlich CAPTCHA-Auflösung, Fingerprinting, Header-Auswahl, automatische Wiederholungen und JavaScript-Rendering.
🤔 Ist Scraping Browser ein Headless- oder ein Headful-Browser?
Der Scraping Browser verwendet eine grafische Benutzeroberfläche und wird auch Headful Browser genannt. Entwickler interagieren jedoch mit Scraping Browser über eine API wie Puppeteer oder Playwright, wodurch es funktional kopflos wird. Scraping Browser wird als GUI-Browser geöffnet Bright Datas Infrastruktur.
👉 Was ist der Unterschied zwischen einem Headless- und einem Headful-Browser, wenn es ums Scraping geht?
Headless-Browser beziehen sich auf Webbrowser ohne grafische Benutzeroberfläche und können zum Scrapen von Daten verwendet werden, wenn sie mit einem Proxy verwendet werden. Sie werden jedoch leicht von Bot-Schutzsoftware erkannt, was ein groß angelegtes Daten-Scraping erschwert. GUI-Browser wie Scraping Browser verwenden eine grafische Benutzeroberfläche und werden mit geringerer Wahrscheinlichkeit von Bot-Erkennungssoftware erkannt.
🤔 Was macht Scraping Browser besser als Chrome Headless oder Python Selenium Web Scraping?
Der Scraping Browser verfügt über eine Funktion zum automatischen Entsperren, die Einschränkungen automatisch entfernt. Es ist möglich, Webdaten-Scraping-Projekte ohne Infrastrukturanforderungen zu skalieren, indem Scraping-Browser verwendet werden, die eine automatische Entsperrung verwenden und weiterlaufen Bright DataDie Server von .
👉 Ist Scraping Browser mit Puppeteer Scraping kompatibel?
Ja, Scraping Browser ist voll kompatibel mit Puppeteer.
🤔 Wann sollte ich den Scraping Browser anstelle von anderen verwenden Bright Data Proxy-Produkte?
Scraping Browser ist ein automatisierter Browser zum Scrapen von Daten, der von der automatischen Entsperrungstechnologie von Web Unlocker unterstützt wird. Das Scraping eines Browsers ist notwendig, wenn ein Entwickler mit einer Website interagieren muss, um ihre Daten abzurufen. Es ist auch ideal für jedes Daten-Scraping-Projekt, das Browser, Skalierung und automatisierte Verwaltung aller Aktionen zum Entsperren von Websites erfordert.
Quick-Links:
Fazit: Bright Data Bewertung des Scraping-Browsers 2024
Zusammenfassend lässt sich sagen, dass Data Scraping eine herausfordernde Aufgabe sein kann, insbesondere wenn es um Website-Blöcke und andere Bot-Erkennungsskripte geht.
Das Bright Data Scraping Browser ist ein automatisierter All-in-One-Browser, der das Daten-Scraping einfacher und effizienter macht.
Mit Puppeteer-Kompatibilität, automatischem Entsperren von Websites, CAPTCHA-Auflösung, Fingerabdrücken, Wiederholungen und mehr bietet es eine Vielzahl von Funktionen und Vorteilen.
Es ist ein hervorragendes Werkzeug zur Skalierung, spart Ressourcen und Zeit und ist ideal für die Abwicklung komplexer Entsperrvorgänge.