What is Web Scraping?
Web scraping is the practice of automatically gathering information from the web. The HTML code of the website is downloaded and parsed (the data is made structured) by your web scraper instead of manually copied.
If you need to gather information from online pages, web scraping is your best option.
Web scraping is frequently utilized by companies, freelancers, and academics because it provides fast, accurate, and comprehensive data collection from the World Wide Web.
Picking the Right Web-Scraping Software
Many different tools exist for web scraping, including library APIs (Requests, BeautifulSoup, Cheerio), frameworks (Scrapy, Selenium), pre-built scrapers (ParseHub, Octoparse), and specialized scrapers (ScrapingBee API, Smartproxy’s SERP API).
Among programmers, Python is far and away the most used choice for web scraping. The voyage is documented using a wide range of resources at its many distinct stages.
When compared to web scraping frameworks, standalone libraries frequently demand the use of additional tools to finish your scraper.
However, pre-made scrapers don’t need you to know how to code.
10 Best Websites to Practice Web Scraping Skills 2024
Here, I have concluded the best websites to practice your web scraping skills.
1. Toscrape
Toscrape serves as a learning and practice environment for web scraping at all levels. The website has two distinct sections. The first is a made-up shop with shelves upon shelves of literature to be culled.
The second features a compilation of great quotations. As such, it is often used as a testbed for various web scraping techniques.
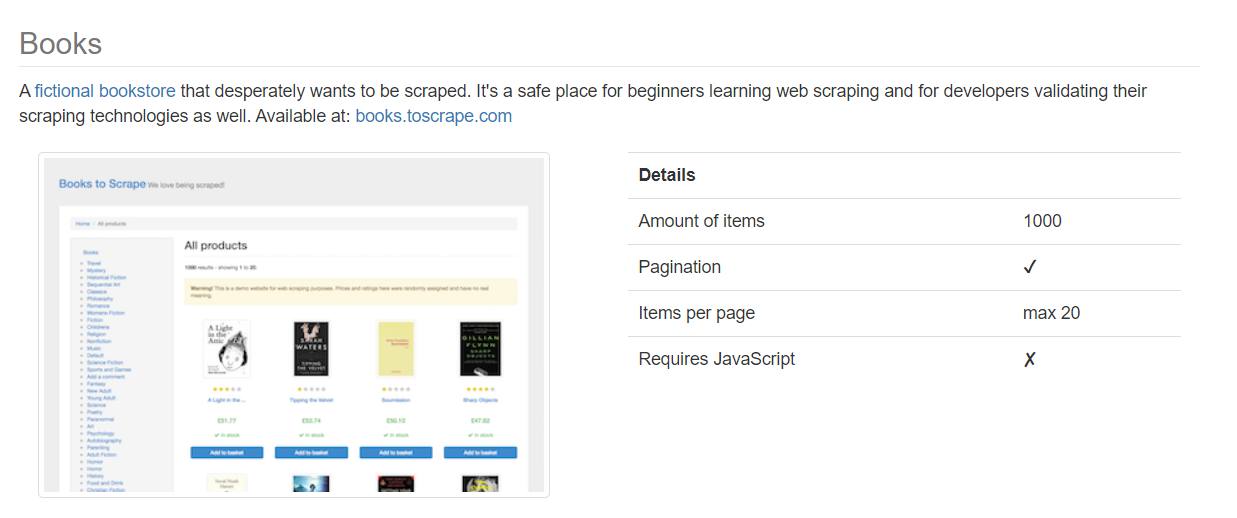
Books.toscrape.com is a great place to hone your data extraction abilities by practicing real-world examples. Since it is entirely static, common libraries like Requests and Beautiful Soup can be used.
Multiple endpoints with difficult tasks are presented in quotes.to scrape.com. It can show you how to sign in and extract data from websites built with JavaScript that uses lazy loading and delayed rendering.
A headless browser may be necessary if you can’t get by only using simple web scraping libraries.
Features
- Designed specifically for web scraping practice.
- Offers a variety of data sets.
- Simulates real-world web structures.
- Provides challenges at different difficulty levels.
- Includes examples of different web page layouts.
- Offers dynamic and static content for scraping.
- Provides a safe and legal environment for scraping practice.
Pros
- Great for learning and improving web scraping skills.
- There is no risk of legal issues as it’s meant for practice.
- A variety of challenges enhances problem-solving skills.
- It helps understand different web technologies.
- Free to use.
- Accessible to beginners and advanced users.
- Encourages ethical scraping practices.
Cons
- It may not represent all types of modern web technologies.
- Does not provide real-time data.
2. Scrapethissite
Similar to Toscrape, Scrapethissite is a wonderful learning environment for web scraping. If you’re just starting, I recommend reading up on static data collecting in Python first.
Some fundamentals, such as scraping tables or titles, may be learned. This site is also a wonderful resource for learning sophisticated data retrieval techniques, such as scraping JavaScript-based material that is produced on the fly.
When you start scraping live websites, you’ll inevitably encounter catches. You should try out CSRF token passing, login spoofing, session cookie management, and other similar exercises.
Features
- Interactive web scraping challenges.
- It covers a range of difficulty levels.
- Provides instant feedback on scraping tasks.
- Includes tutorials and guides.
- Simulates various web page structures.
- Offers a community forum for discussion.
- Provides a leaderboard for competitive learning.
Pros
- Excellent for hands-on learning of web scraping.
- Interactive challenges make learning engaging.
- Suitable for both beginners and experienced scrapers.
- Community support for problem-solving.
- Real-time feedback aids in quick learning.
- A free resource for learning.
- Encourages ethical scraping practices.
Cons
- It may not cover advanced scraping scenarios.
- It is not representative of scraping real, complex websites.
- It can be too basic for highly experienced scrapers.
3. Yahoo! Finance
Yahoo! Finance is a great location to get some real-world experience with web scraping. There are millions of recent financial records in this vast database, and they all provide the latest information on the stock market and firms.

What are the attainable abilities? Text may be easily scraped from the site since everything is neatly organized in tables on distinct pages.
So, you may get some experience with data mining by scraping tables and graphs. You can conduct some math crunching, extract stock and financial statement data, and track price movements.
If you want to use Python to compute stock returns, I suggest first organizing online data into a comma-separated value (.csv) file format or an Excel Spreadsheet.
Features
- Real-time stock market data and news.
- Financial analysis and reports.
- Portfolio management tools.
- Historical data and trends.
- Global market coverage.
- Customizable watchlists.
- Financial calendar with earnings and economic events.
Pros
- A comprehensive source of financial information.
- User-friendly interface for tracking investments.
- Real-time data aids in timely decision-making.
- Wide range of tools for personal finance management.
- Access to expert analysis and opinions.
- Mobile app for on-the-go access.
- Integration with other Yahoo services.
Cons
- Premium features require a subscription.
- Ads can be intrusive in the free version.
4. Wikipedia
Since so much information is already there in HTML5 format, Wikipedia is a great place to get some experience. There is a dedicated section for studying how to work with IDs and properties.
Scraping tables, pictures, and graphs is another option for practicing the fundamentals. If your scraper moves too quickly, though, you risk having your passage blocked.
Features
- Free online encyclopedia.
- User-generated and edited content.
- Articles in multiple languages.
- Extensive coverage of a vast array of topics.
- Includes references and external links.
- Regularly updated content.
- Offers a simple and advanced search function.
Pros
- Easily accessible and free to use.
- Wide range of topics covered.
- Generally reliable for basic information.
- Community monitoring helps maintain accuracy.
- Multilingual support.
- Simple to navigate and use.
- Regular updates keep content current.
Cons
- Potential for inaccuracies and bias.
5. Reddit
If you want to follow the forum route, I recommend getting your hands dirty on Reddit. Users may upload media such as photos and movies by using the site’s standard URL structure.

You may see which comments or images received the most upvotes, which phrases were used often in a certain subreddit, or how the general public felt about a particular news story.
By web scraping a discussion board, you may learn the fundamentals of web scraping while perhaps discovering a lucrative business opportunity.
Features
- User-generated content in subreddit communities.
- Wide range of topics and interests.
- The ability for users to comment and discuss.
- Customizable feeds based on user subscriptions.
- Anonymous posting options.
- Regular updates and new content.
Pros
- A diverse range of communities and topics.
- Real-time updates on trends and news.
- User moderation helps manage content quality.
- A platform for open discussions and debates.
- Customizable to user interests.
- The large user base for wide perspectives.
- Mobile app for access anywhere.
Cons
- Overwhelming for new users.
- Privacy concerns with user data.
6. Twitter
Twitter has over 145 million daily active users and 330 million monthly active users. The sheer volume of its members has transformed Twitter from a simple social network into a powerful promotional tool.
Industrial research, sentiment analysis, customer experience management, etc., are just some of the uses for Twitter data.
Features
- Microblogging with a character limit.
- Real-time updates and news.
- User profiles with followers/following system.
- Hashtags for trending topics.
- Direct messaging for private conversations.
- Integration with various media (images, videos, links).
- Verification system for public figures and organizations.
Pros
- Quick access to breaking news and trends.
- Wide reach and diverse user base.
- Easy to use and navigate.
- Effective for networking and communication.
- The platform for influencers and public figures.
- Mobile app for convenience.
- Allows for direct interaction with audiences.
Cons
- Limited depth due to character restriction.
7. Indeed
Indeed claims that they have received 175 million resumes since it first opened its doors. It’s become second nature to hunt for work online; most of us have forgotten what a physical job fair looks like.
In recent years, it has become a lucrative business to create a job aggregator, particularly for specialized sectors. Guess how they get it off! The secret lies in web scraping, indeed.
Data from employment sites is useful for more than just those who construct job boards. Jobs data is highly sought after by HR specialists, job-seekers, potential job-hoppers, and academics interested in recruiting and labor markets.
Having a broad understanding of the labor market might help you negotiate better wages and benefits.
Features
- Job listings from various sources.
- Resume upload and job application features.
- Company reviews and salary comparisons.
- Job alerts and recommendations.
- Search filters for location, salary, job type, etc.
- User accounts for managing applications.
- Mobile app for job searching on the go.
Pros
- Extensive database of job listings.
- User-friendly interface and search functionality.
- Helpful resources like company reviews and salary data.
- Personalized job recommendations.
- Free to use for job seekers.
- Resume builder and other career tools.
- Global reach with listings in multiple countries.
Cons
- Some listings may be outdated or no longer available.
- User experience can vary based on location.
8. Google
With its advanced machine learning algorithm, Google may soon become the artificial intelligence that understands its users better than their relatives and friends. That’s just a matter of fact.
What, if anything, can we get from Google as individuals? An Internet search may be of greatest interest to SEO marketers. TDK (short for Title, Description, Keywords) data is collected by scraping Google search results for a set of keywords to drive an SEO optimization plan.
TDK is the metadata of a web page that appears in the result list and has a crucial effect on the click-through rate.
Features
- Powerful search engine capabilities.
- Image, video, and news search.
- Integrated with other Google services (Maps, Drive, Gmail).
- Personalized search results.
- Voice search functionality.
- Advanced search options and filters.
- Mobile app for easy access.
Pros
- Dominant search engine with a vast index.
- Highly relevant and fast search results.
- User-friendly and intuitive interface.
- Integration with other Google services enhances functionality.
- Constant updates and improvements.
- Strong security features.
- Multilingual support.
Cons
- Privacy concerns due to data tracking.
9. eBay
Web scraping is most common among e-commerce sites, and eBay is no exception. Many of our customers operate their own companies on eBay, and for them, access to eBay’s data is crucial for staying abreast of the competition and the market as a whole.
One client experience stands out to me as particularly remarkable.
The client is an eBay vendor that routinely scrapes information from eBay and other e-commerce platforms to compile a comprehensive database for in-depth market analysis.
Features
- Online auction and shopping platform.
- Wide range of products from various sellers.
- User rating and feedback system.
- Buy Now and auction buying options.
- Seller stores and personal profiles.
- Global shipping program for international buyers.
- Secure payment options, including PayPal.
Pros
- Diverse range of products, including rare and unique items.
- Competitive pricing through auctions.
- User feedback system helps gauge seller credibility.
- Protection policies for buyers and sellers.
- Easy to use interface.
- Mobile app for shopping on the go.
- Opportunities for small businesses and individual sellers.
Cons
- Quality of products can be inconsistent.
10. Amazon
It’s no big surprise that Amazon is one of the most scrapped sites out there. Since Amazon controls such a large percentage of the e-commerce market, its data is the most applicable to any study of the sector.

They have the biggest information bank. However, there are obstacles to collecting e-commerce statistics.
Quick Links:
- 10+ Best Antidetect Browsers
- 9 Best Proxy Switchers
- Best Libgen Proxy Sites and Mirrors (Works 100%)
- [Updated] List of Best Free Proxy Servers
Conclusion: Best Websites to Practice Web Scraping Skills 2024
While data is the new oil, not everyone has the means to extract its full value. Data is difficult to obtain for the general public, but you can practice web scraping using these websites.
In this manner, we may all have access to the relevant information and use it to improve the planet.